
I spent some time to understand the Watson Retrieve and Rank service. Below are some findings that might help people to learn about the power of this cognitive service that is available in IBM Bluemix.
Here is the description of the service from the Watson Developer Cloud:
This service helps users find the most relevant information for their query by using a combination of search and machine learning algorithms to detect ‘signals’ in the data. Built on top of Apache Solr, developers load their data into the service, train a machine learning model based on known relevant results, then leverage this model to provide improved results to their end users based on their question or query.
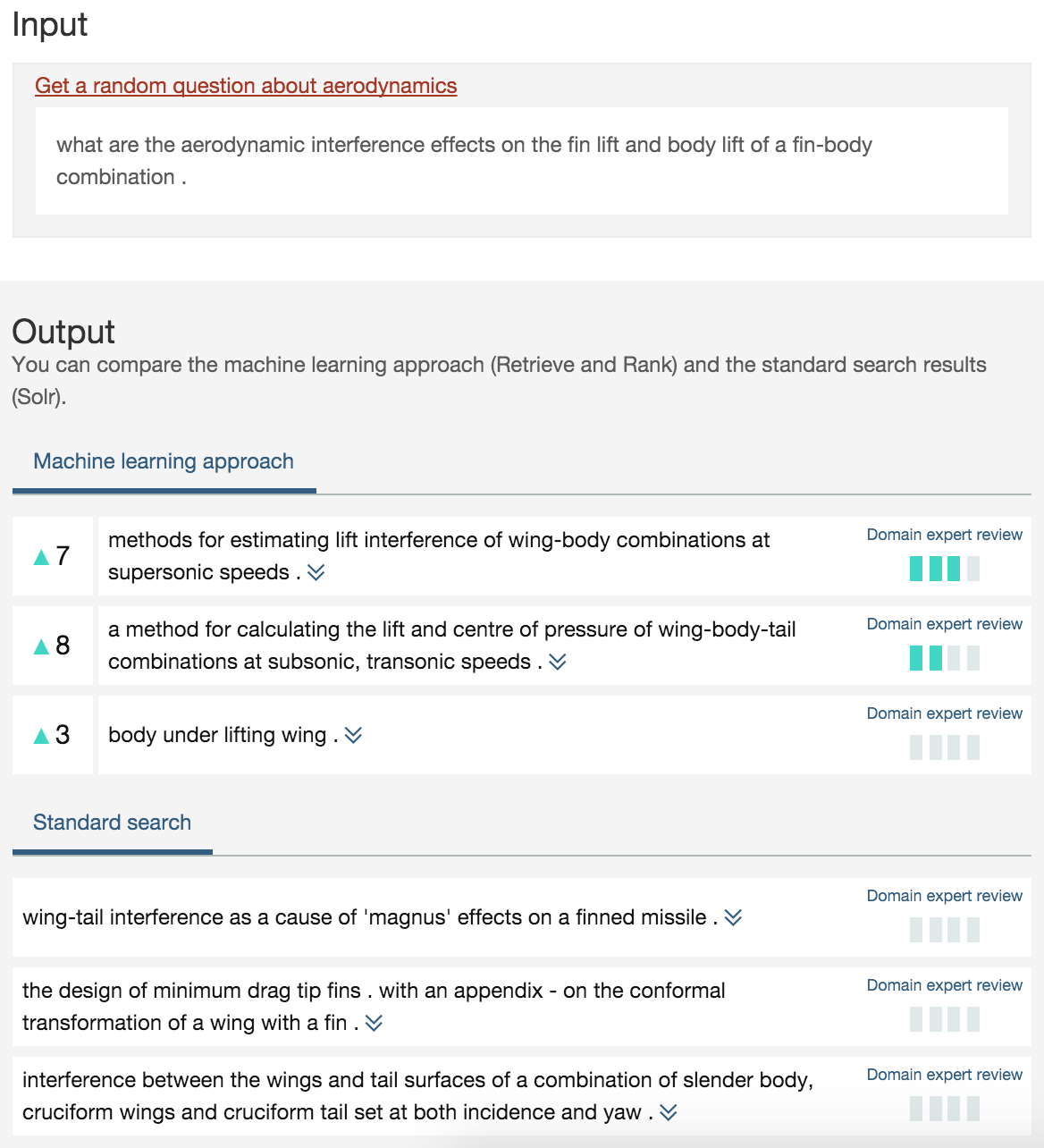
As for every Watson service there is an online demo you can try. The demo uses a publically available data set, the Cranfield collection, which is data about aerodynamics. The same query is invoked against Apache Solr and against the Retrieve and Rank service so that you can compare the quality of the results. Since most people are not aerodynamics experts the sample also lists how domain experts have rated the results (right column). The left column shows how much higher or lower the Retrieve and Rank service ranks certain documents compared to Solr.
In order to get started you can set up this demo yourself. Essentially you need to create a Solr cluster in the cloud, add your documents and create a ranker by providing a ‘Ground Truth’ file to generate the training data for the machine learning algorithm the ranker uses. In the Ground Truth file you define sample questions and for each question a list of documents and relevance information that are related to the question.
Here are some key concepts that I learned:
- The Retrieve and Rank service is a search-based system. The ranker is run based on the results of the Solr search. If Solr doesn’t find anything, Retrieve and Rank won’t either.
- The key is to define a good Ground Truth file. As my colleagues told me several of our customers create this by running Solr searches and subject matter experts determine what good results are and score them. This process is repeated over time to refine the model.
- In difference to the natural language classifier service, the Retrieve and Rank service does not utilize text from the Ground Truth file directly. For example the ranker does not detect synonyms. In order to handle synonyms you need to define them in the Solr configuration.
- The ranker gets feature scores from the previous retrieve step which contains numbers only. The retrieve component invokes standard search queries and compares the input text with the fields defined in your schema and Solr configuration. For each comparison you get multiple feature scores that are based on various text similarity algorithms. The ranker receives the feature scores and understands which feature values are dominant in the applied domain via machine learning. Fortunately consumers of this service don’t have to understand (most of) this complexity.