
Watson Discovery is an IBM offering to search and analyze information in various types of documents. This post describes how domain experts can improve search results by training the Discovery service.
Search results from Google are incredibly good. However, they are not and cannot be optimzed for all specific domains. Watson Discovery provides a mechanism for domain experts to rank search results. Based on these rankings future search results can be improved.
Let’s take a look at a concrete scenario. When users search for ‘Watson Embed’ in my blog, they should see the articles related to Watson NLP and Watson Speech and not the ones related to Watson in general or other articles that mention the term ’embedded’.
Via ranking Discovery can be better than generic search engines like Google. For example, when searching for ‘What is Embeddable AI’ Google returns several good articles, but also some that are not related. As long as Discovery hasn’t been trained, it cannot provide better results either.
To train Watson Discovery, the data needs to be added first. Websites like my blog can be crawled.
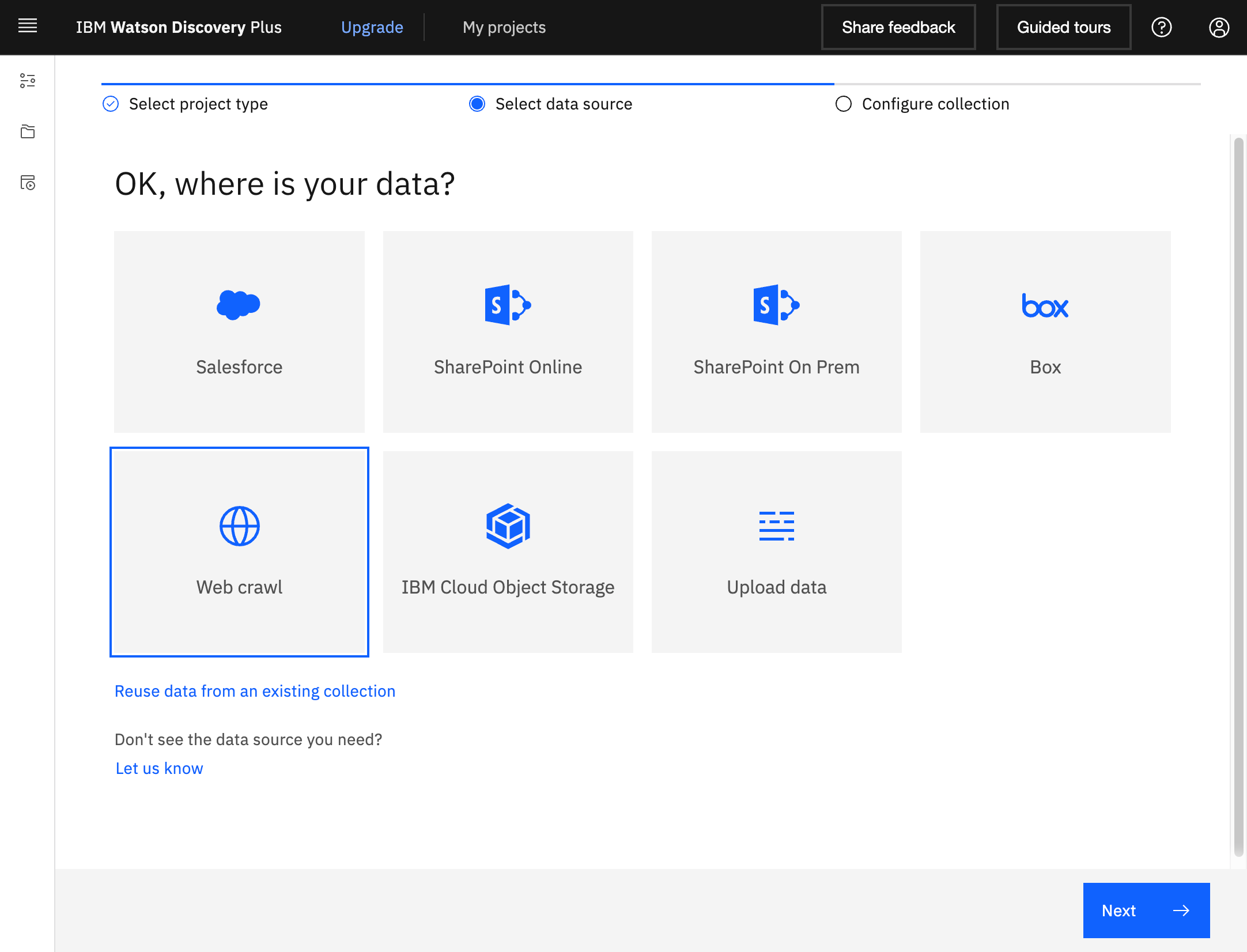
Domain experts can use Watson Discovery’s relevance ranking feature to define whether or not search results are relevant.
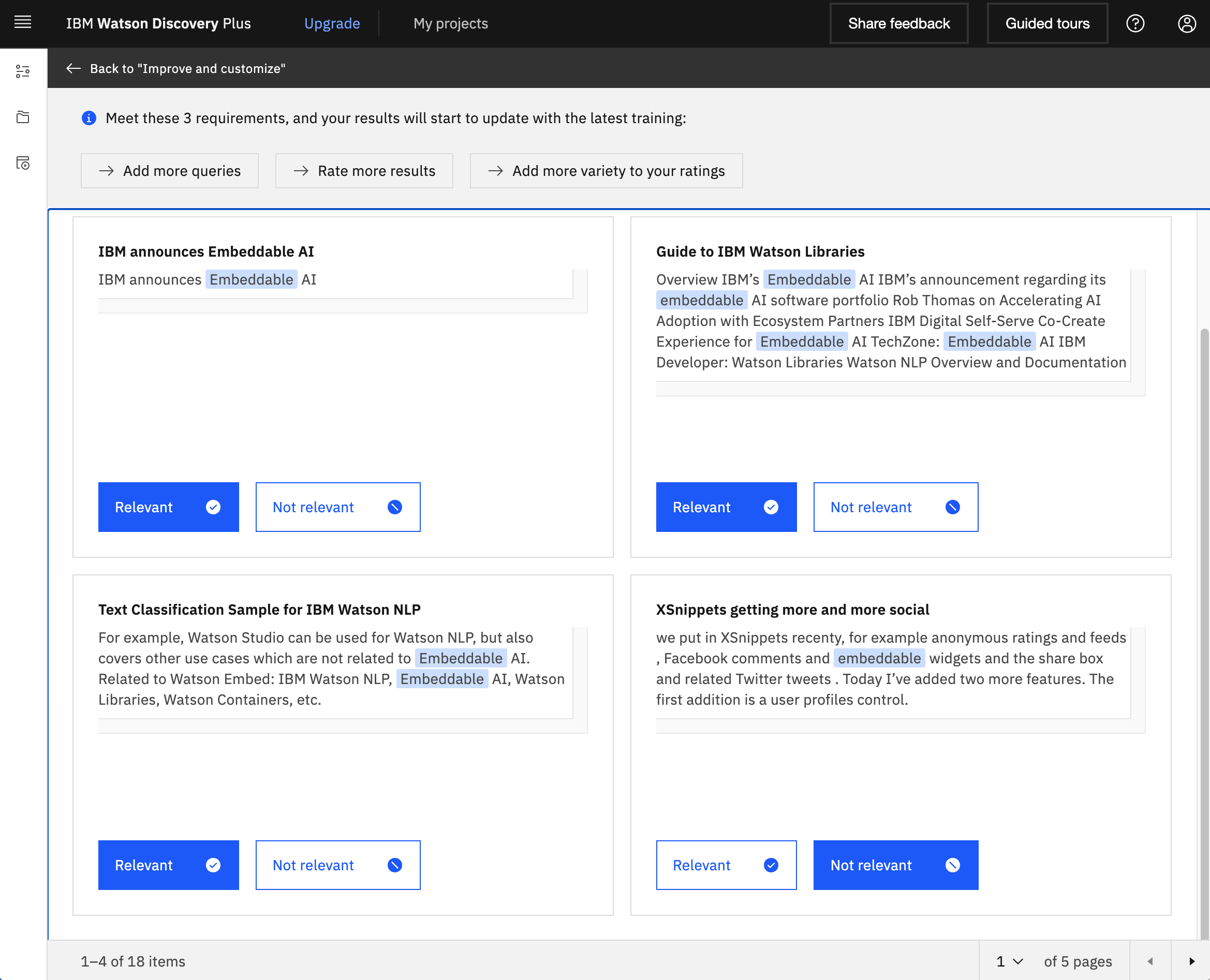
After the training the search results have been improved. All ten search results on the first page are now related to Watson Embed.
To learn more about relevance ranking, check out the Watson Discovery documentation.