
Before the actual fine-tuning of Large Language Models can start, data needs to be prepared and the code needs to be checked whether it works. This post describes how to do this efficiently locally.
Fine-tuning Large Language Models requires GPUs which are typically deployed on servers in the cloud. These GPUs can be rather expensive which is why as much of the work as possible should be prepared on cheaper hardware, for example CPUs on development machines.
Container
When using the Hugging Face Trainer and Transformers API for the fine-tuning, a standard Ubuntu image can be run locally via containers.
1
2
3
alias docker=podman
cd ${Home}
docker run -it -v "$PWD":/nik --name localtune ubuntu
To start the container again, run these commands:
1
2
docker start localtune
docker exec -it localtune bash
Dependencies
Install Python and PyTorch.
1
2
3
4
5
6
apt update
apt upgrade
apt install python3
apt install python3-pip
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
apt install nano
Next install the necessary Hugging Face libraries. Note that I had to use the exact versions below. The latest versions did not work for me.
1
2
3
4
pip install "accelerate==0.17.1"
pip install "peft==0.2.0"
pip install "transformers==4.27.2" "datasets" "evaluate==0.4.0" "bitsandbytes==0.41.2.post2" loralib
pip install rouge-score tensorboard py7zr scipy openpyxl
Data
For fine-tuning high quality data is needed with ground truth information for certain inputs. The example below uses the following structure.
| input | output_ground_truth |
|---|---|
| input 1 | output ground truth 1 |
| input 2 | output ground truth 2 |
| … | … |
Note that the quality of the data is really important. If the data is not accurate, the model cannot deliver good results. Quantity is also important. Typically, you need thousands of samples. If you don’t have enough, you might want to consider creating synthetic data.
Example
The example below is copied from the article Efficient Large Language Model training with LoRA and Hugging Face.
Data is split in training and evaluating datasets. Tokenization is done via the tokenizer from FLAN T5.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
ground_truth = "ground-truth.xlsx"
sheet = "main"
model_id="google/flan-t5-xl"
prompt_instruction="Input: "
from pandas import read_excel
ground_truth_df = read_excel(ground_truth, sheet_name = sheet)
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained(model_id)
def preprocess_features(features_sample):
# modify if necessary
return features_sample
features_column = ground_truth_df['output_ground_truth']
new_features_column = features_column.apply(preprocess_features)
ground_truth_df['output_ground_truth'] = new_features_column
df_train = ground_truth_df.sample(frac = 0.8)
df_test = ground_truth_df.drop(df_train.index)
print("Amount data for training: " + str(len(df_train)))
print("Amount data for testing: " + str(len(df_test)))
from datasets import Dataset, DatasetDict
dataset = DatasetDict({
"train": Dataset.from_pandas(df_train),
"test": Dataset.from_pandas(df_test)
})
from datasets import concatenate_datasets
import numpy as np
tokenized_inputs = concatenate_datasets([dataset["train"], dataset["test"]]).map(lambda x: tokenizer(x["input"], truncation=True), batched=True, remove_columns=["input", "output_ground_truth"])
input_lenghts = [len(x) for x in tokenized_inputs["input_ids"]]
max_source_length = int(np.percentile(input_lenghts, 85))
print(f"Max source length: {max_source_length}")
tokenized_targets = concatenate_datasets([dataset["train"], dataset["test"]]).map(lambda x: tokenizer(x["output_ground_truth"], truncation=True), batched=True, remove_columns=["input", "output_ground_truth"])
target_lenghts = [len(x) for x in tokenized_targets["input_ids"]]
max_target_length = int(np.percentile(target_lenghts, 90))
print(f"Max target length: {max_target_length}")
def preprocess_function(sample,padding="max_length"):
inputs = [prompt_instruction + item for item in sample["input"]]
model_inputs = tokenizer(inputs, max_length=max_source_length, padding=padding, truncation=True)
labels = tokenizer(text_target=sample["output_ground_truth"], max_length=max_target_length, padding=padding, truncation=True)
if padding == "max_length":
labels["input_ids"] = [
[(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
]
model_inputs["labels"] = labels["input_ids"]
return model_inputs
tokenized_dataset = dataset.map(preprocess_function, batched=True)
tokenized_dataset["train"].save_to_disk("data/train")
tokenized_dataset["test"].save_to_disk("data/eval")
print('''tokenized_dataset["train"][0]"''')
print(tokenized_dataset["train"][0])
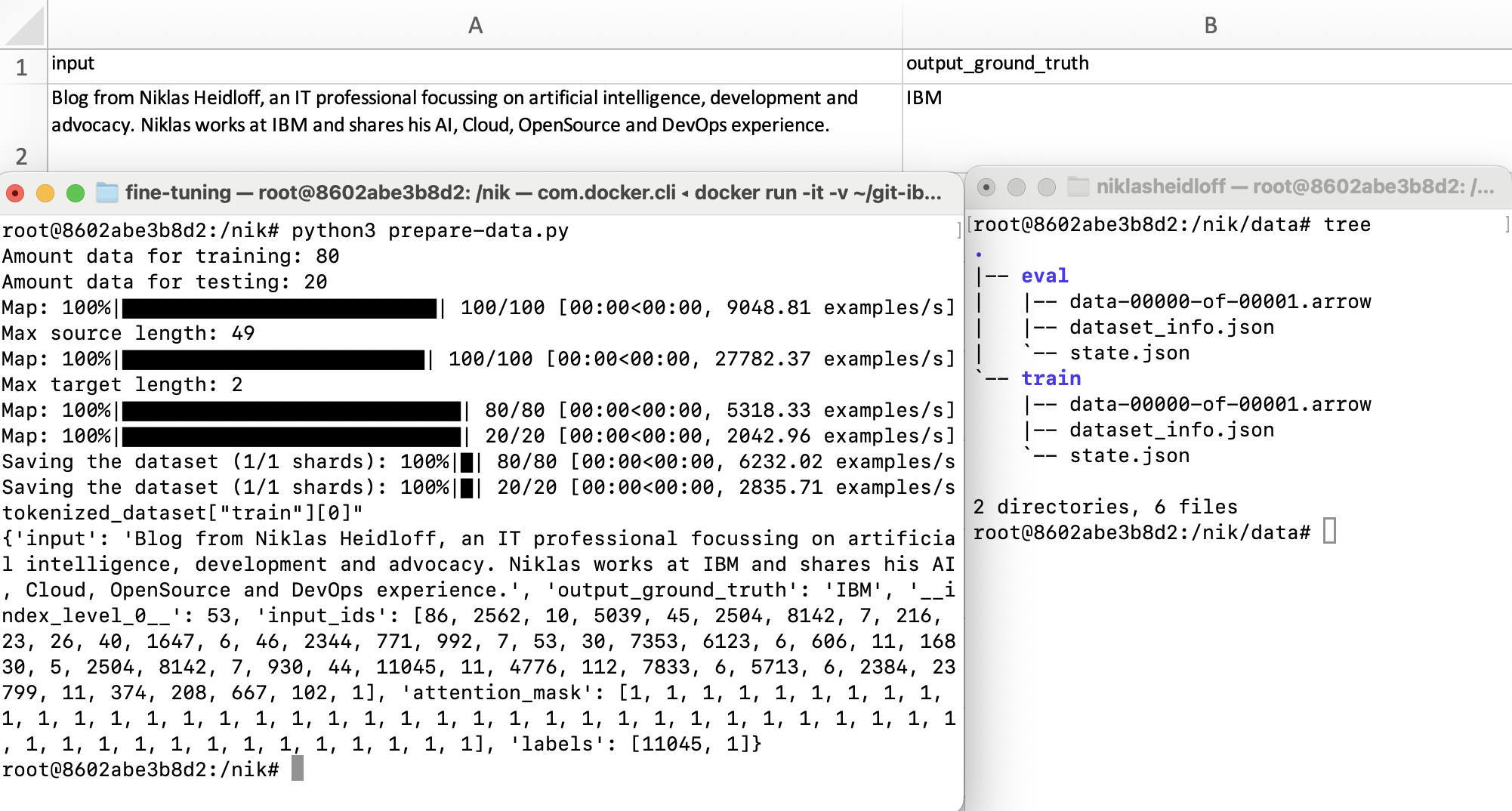
The script produces this output:
1
2
3
4
5
6
7
8
9
10
11
12
13
$ python3 prepare-data.py
Amount data for training: 80
Amount data for testing: 20
Map: 100%|██████████████████████████████████████████| 3/3 [00:00<00:00, 362.82 examples/s]
Max source length: 49
Map: 100%|██████████████████████████████████████████| 3/3 [00:00<00:00, 968.89 examples/s]
Max target length: 2
Map: 100%|██████████████████████████████████████████| 2/2 [00:00<00:00, 425.90 examples/s]
Map: 100%|██████████████████████████████████████████| 1/1 [00:00<00:00, 287.73 examples/s]
Saving the dataset (1/1 shards): 100%|██████████████| 2/2 [00:00<00:00, 275.15 examples/s]
Saving the dataset (1/1 shards): 100%|██████████████| 1/1 [00:00<00:00, 185.49 examples/s]
tokenized_dataset["train"][0]"
{'input': 'Blog from Niklas Heidloff, an IT professional focussing on artificial intelligence, development and advocacy. Niklas works at IBM and shares his AI, Cloud, OpenSource and DevOps experience.', 'output_ground_truth': 'IBM', '__index_level_0__': 2, 'input_ids': [86, 2562, 10, 5039, 45, 2504, 8142, 7, 216, 23, 26, 40, 1647, 6, 46, 2344, 771, 992, 7, 53, 30, 7353, 6123, 6, 606, 11, 16830, 5, 2504, 8142, 7, 930, 44, 11045, 11, 4776, 112, 7833, 6, 5713, 6, 2384, 23799, 11, 374, 208, 667, 102, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'labels': [11045, 1]}
The two datasets are stored on disc.
1
2
3
4
5
6
7
8
9
10
11
$ tree
.
├── data
├── eval
│ ├── data-00000-of-00001.arrow
│ ├── dataset_info.json
│ └── state.json
└── train
├── data-00000-of-00001.arrow
├── dataset_info.json
└── state.json
When fine-tuning models for only one AI task, the instruction in the prompt doesn’t matter. Since it’s the same for all samples, it’s ignored by the large language model. When tuning models for multiple tasks, you should use different instructions.
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.