
The first Large Language Models only returned plain text. Later models learned how to return JSON which is important for agents and Function Calling. This post summarizes how modern models can even return structured data following specific schemas.
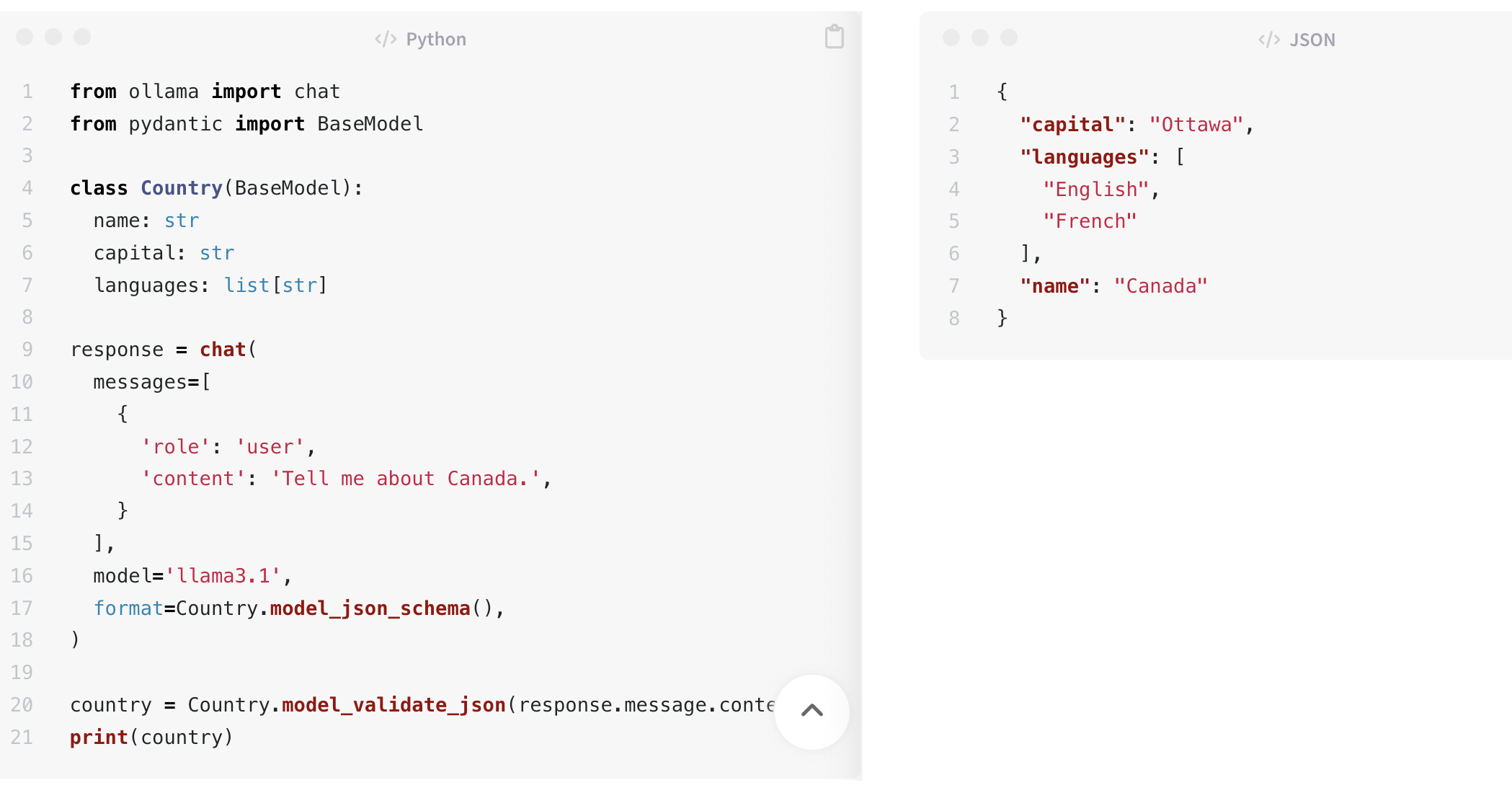
Let’s look at a simple example using Ollama, Llama 3.1 and Pydantic.
Ollama
Since recently Ollama supports Structured Outputs. In the following curl request the expected output schema is defined. For questions like “Tell me about Canada” JSON should be returned containing the name, the capital and a list of spoken languages for a country.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
curl -X POST http://localhost:11434/api/chat -H "Content-Type: application/json" -d '{
"model": "llama3.1",
"messages": [{"role": "user", "content": "Tell me about Canada."}],
"stream": false,
"format": {
"type": "object",
"properties": {
"name": {
"type": "string"
},
"capital": {
"type": "string"
},
"languages": {
"type": "array",
"items": {
"type": "string"
}
}
},
"required": [
"name",
"capital",
"languages"
]
}
}' | jq
The previous command returns the following output.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{
"model": "llama3.1",
"created_at": "2025-02-18T15:01:22.307963Z",
"message": {
"role": "assistant",
"content": "{ \"name\": \"Canada\", \"capital\": \"Ottawa\", \"languages\": [\"English\", \"French\"] }"
},
"done_reason": "stop",
"done": true,
"total_duration": 1281989833,
"load_duration": 33499792,
"prompt_eval_count": 16,
"prompt_eval_duration": 210000000,
"eval_count": 27,
"eval_duration": 1037000000
}
To make it more readable, here is the JSON of the generated text.
1
2
3
4
5
6
7
8
{
"capital": "Ottawa",
"languages": [
"English",
"French"
],
"name": "Canada"
}
If there is no output schema defined, the classic text generation is run.
1
2
3
4
5
curl -X POST http://localhost:11434/api/chat -H "Content-Type: application/json" -d '{
"model": "llama3.1",
"messages": [{"role": "user", "content": "Tell me about Canada."}],
"stream": false
}' | jq
I’ve shortened the output and only kept the key information.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
{
"model": "llama3.1",
"created_at": "2025-02-18T15:15:35.953624Z",
"message": {
"role": "assistant",
"content": "Canada! The Great White North, as it's affectionately known, [cut]...[/cut] major cities like Toronto and Ottawa.\n6. **Quebec**: Known for its French-Canadian culture, historic city of Quebec, and picturesque countryside [cut]...[/cut] n1. **Two official languages**: English and French are the country's official languages.\n2. [cut]...[/cut]"
},
"done_reason": "stop",
"done": true,
"total_duration": 27864512583,
"load_duration": 35987750,
"prompt_eval_count": 16,
"prompt_eval_duration": 184000000,
"eval_count": 733,
"eval_duration": 27643000000
}
Pydantic
The same functionality can be invoked from applications implemented in Python, JavaScript and other languages. Pydantic is a common tool to do this in Python.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from ollama import chat
from pydantic import BaseModel
class Country(BaseModel):
name: str
capital: str
languages: list[str]
response = chat(
messages=[
{
'role': 'user',
'content': 'Tell me about Canada.',
}
],
model='llama3.1',
format=Country.model_json_schema(),
)
country = Country.model_validate_json(response.message.content)
print(country)
How it works
When I ran the snippets above, I assumed that some post processing occurs to convert the plain text into structured output. However, the response times for the plain text requests took longer than the shorter structured output requests.
I’ve found the following resources that describe how this mechanism works.
The language model produces tokens with an associated probability (logit) - llama.cpp uses the grammar to work out which tokens are valid according to the current state. Any tokens that are not valid as the next token according to the grammar are masked (forbidden) during the sampling stage of the LLM output. … The model doesn’t ‘know’ that there is masking of its output tokens going on using a grammar. However, once the logit manipulation has caused it to generate a few tokens of JSON, the model then has that context to help it produce the rest of its output.
GBNF is a format for defining formal grammars to constrain model outputs in llama.cpp. For example, you can use it to force the model to generate valid JSON.
Rather than greedy decoding, sampling is used where the expected schema determines which next tokens are accepted. In the example above this leads to the faster response times since fewer tokens are generated.
Next Steps
With watsonx.ai Agent Lab agentic applications are generated which utilize the functionality above. I’ll blog about this soon.