
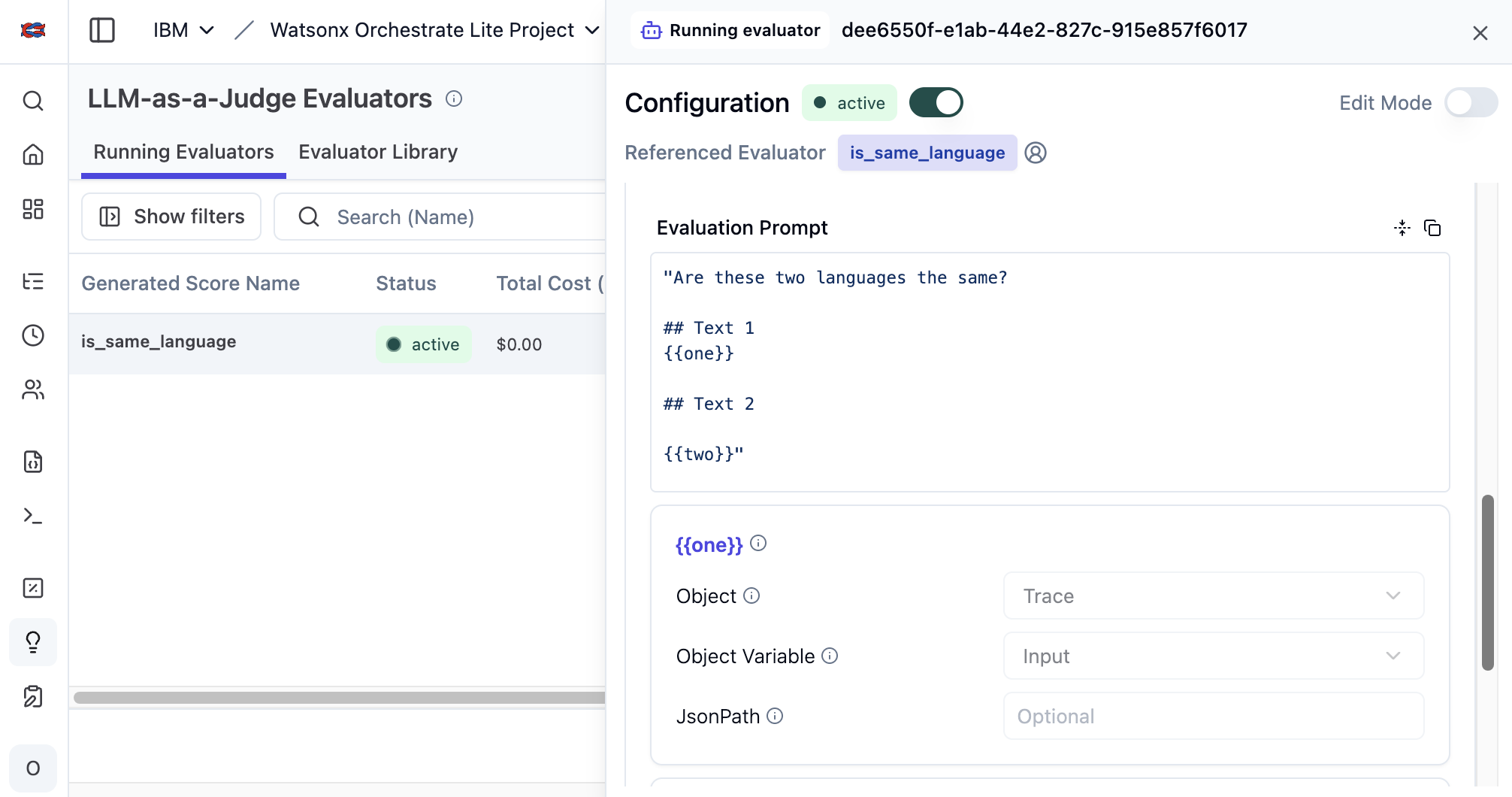
Evaluations of non-deterministic agentic systems are important in the development phase and when running them in production. Separate Large Language Models can help to run these evaluations. This post describes how to use LLM-as-a-Judge in Langfuse.
Often there is no or not enough ground truth data to compare outcomes of agents with the best possible answers at development time. When agents are running in production, users can instruct agents as they like in which case ground truth data cannot be utilized anyway. In both scenarios LLM-as-a-Judge is a powerful technique to evaluate agents without having to have ground truth data and without having to have human experts who evaluate manually.
Langfuse is an open-source LLM engineering platform. In addition to managing traces, it also provides functionality to evaluate models, prompts and agents.
Langfuse comes with a list of pre-defined evaluators:
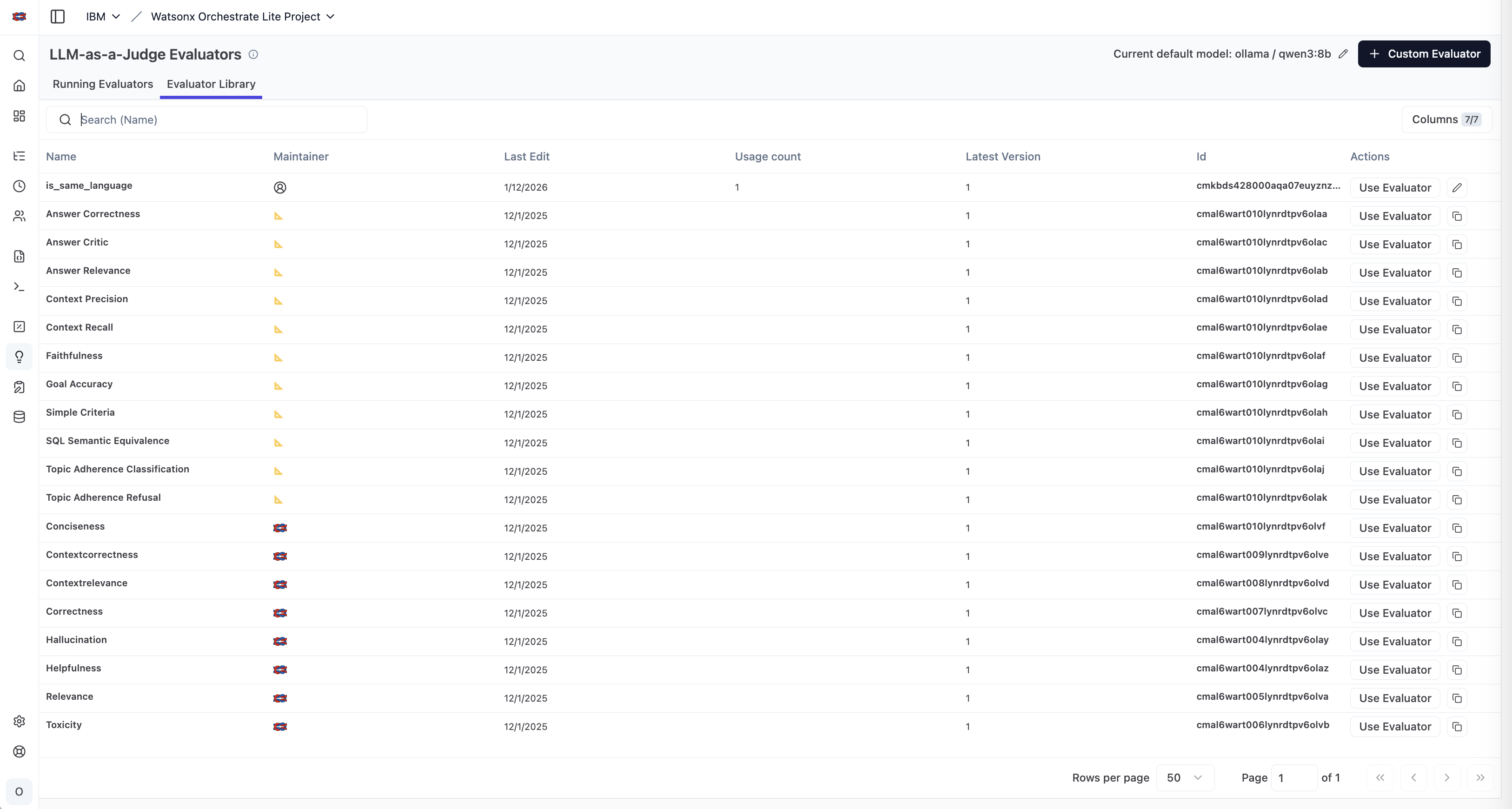
Custom Evaluators
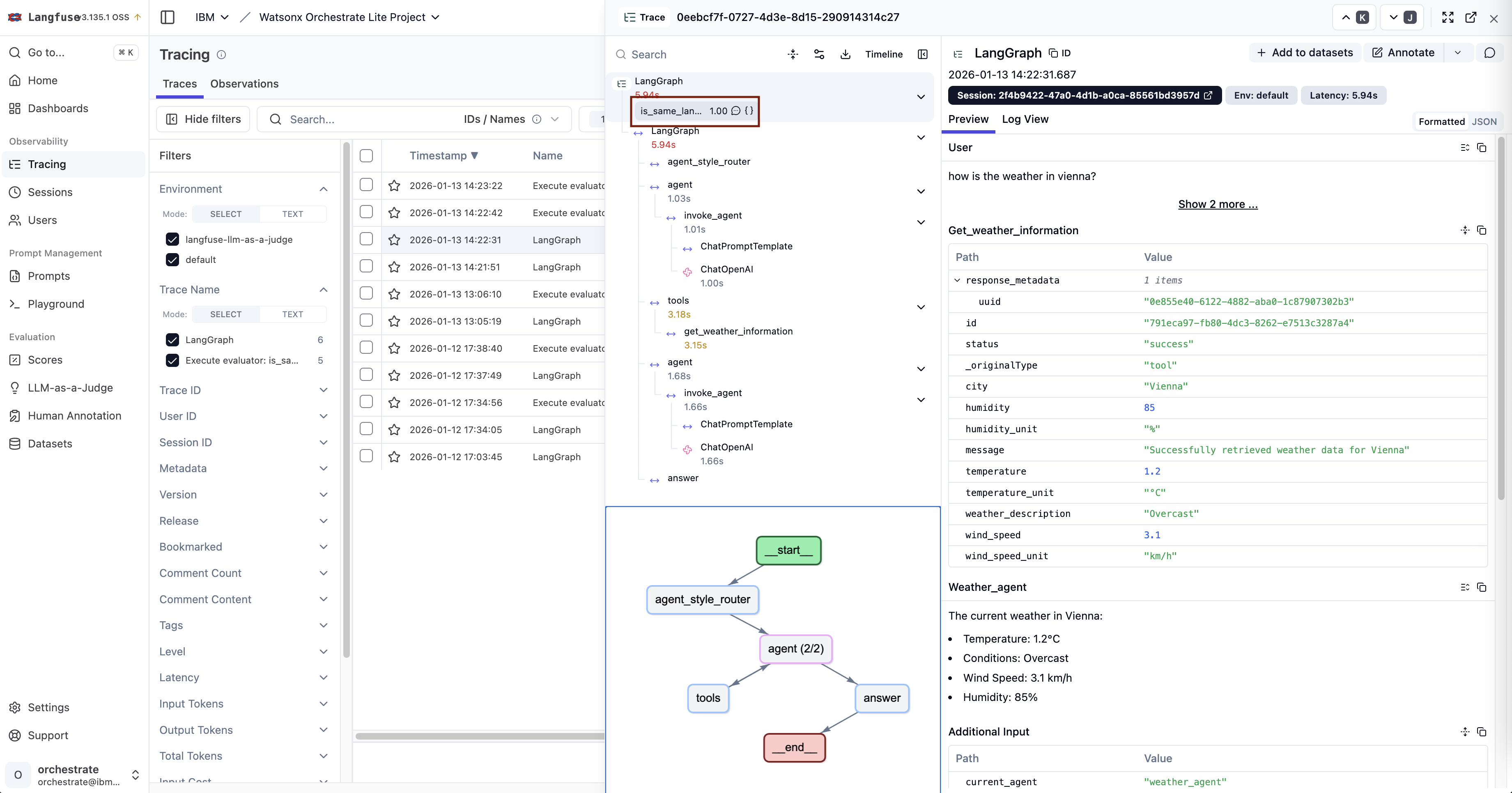
As shown in the image at the top of this post, custom evaluators can be defined, simply by using prompting. The example prompt compares whether the language of the input is the same one as the language of the output.
To use LLM-as-a-Judge you need a Large Language Model. In the following sample it’s a local model, but typically larger models work better.
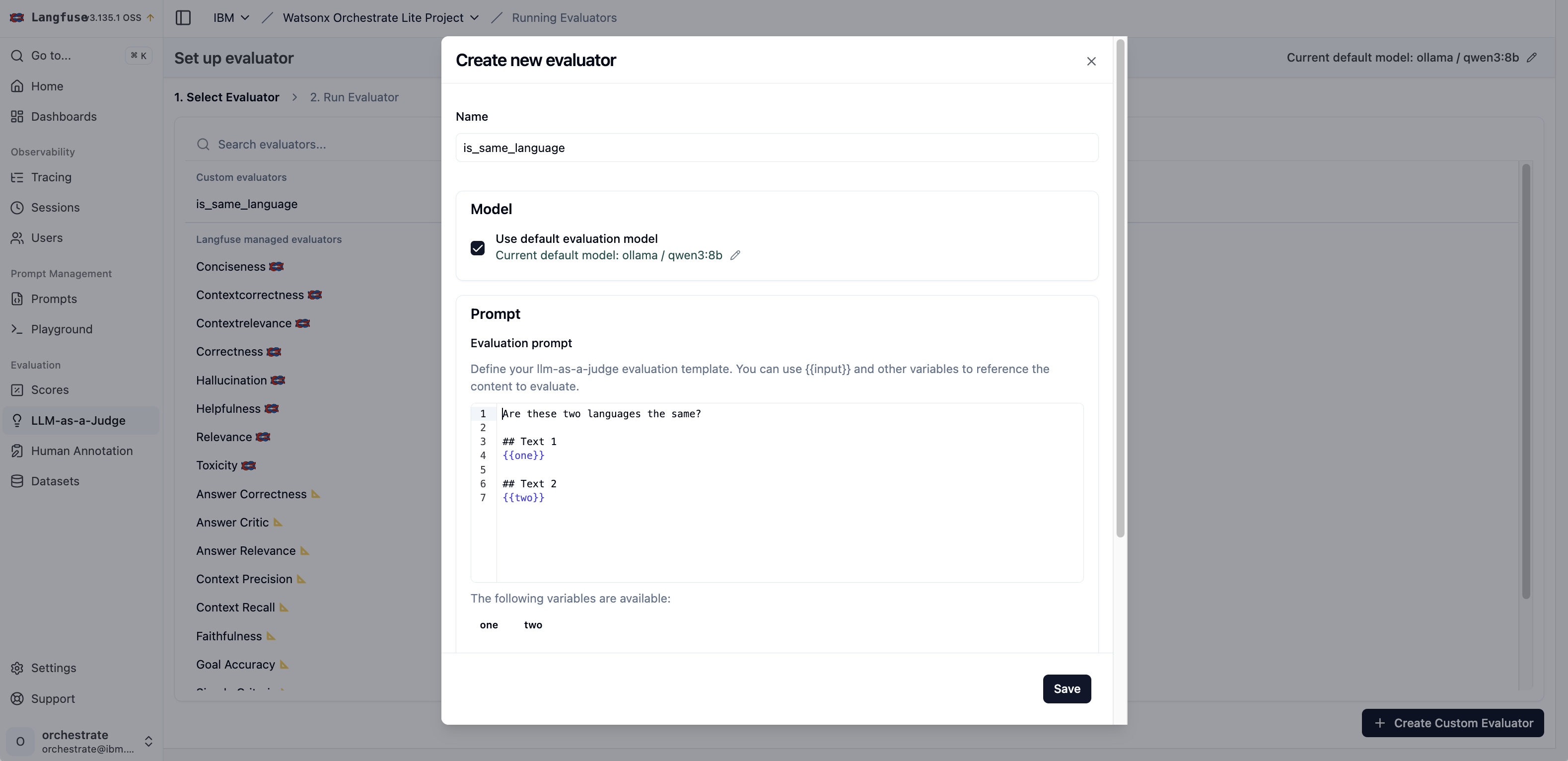
As part of the prompt variables can be defined. Their values are read from the traces. Via JSONPath nested data in the traces can be addressed.
The evaluators can be run on existing or new traces.
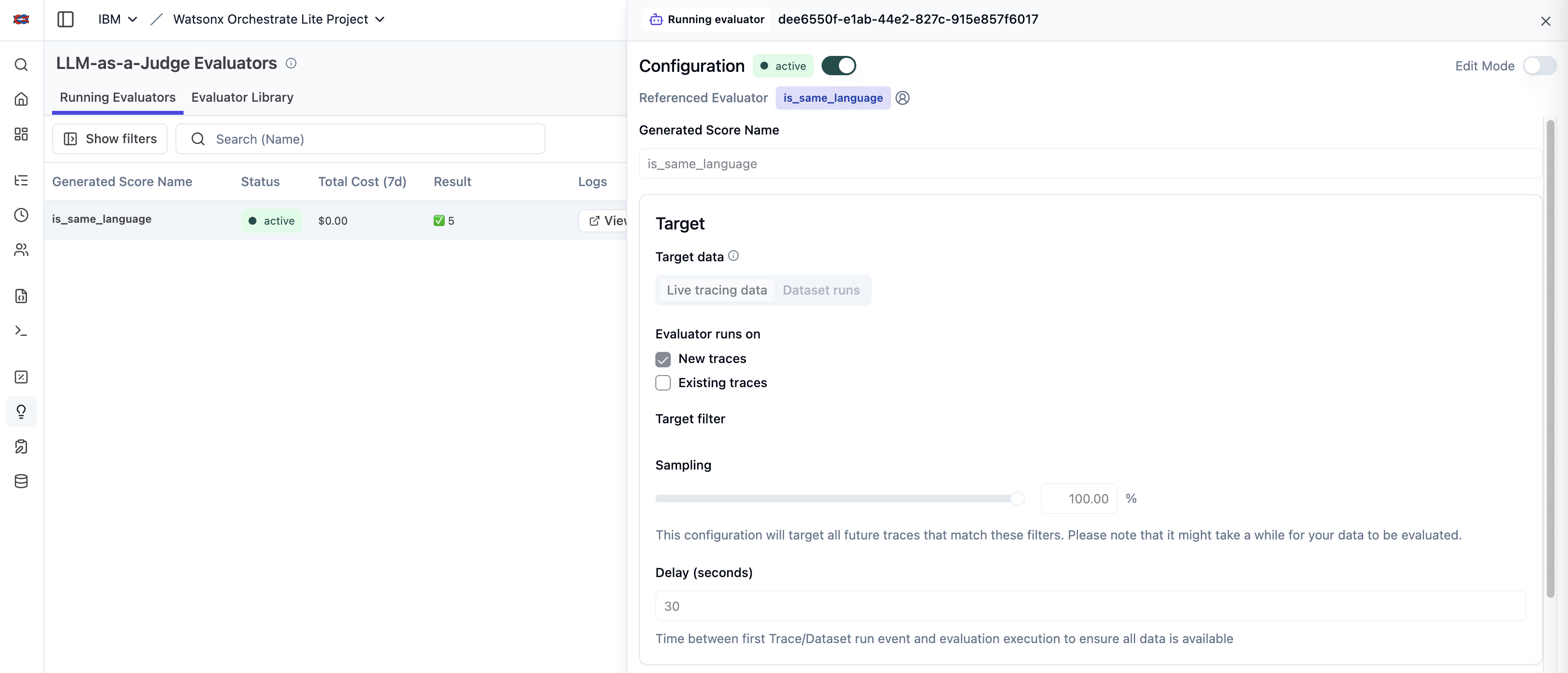
Results
The results show up in the traces directly.
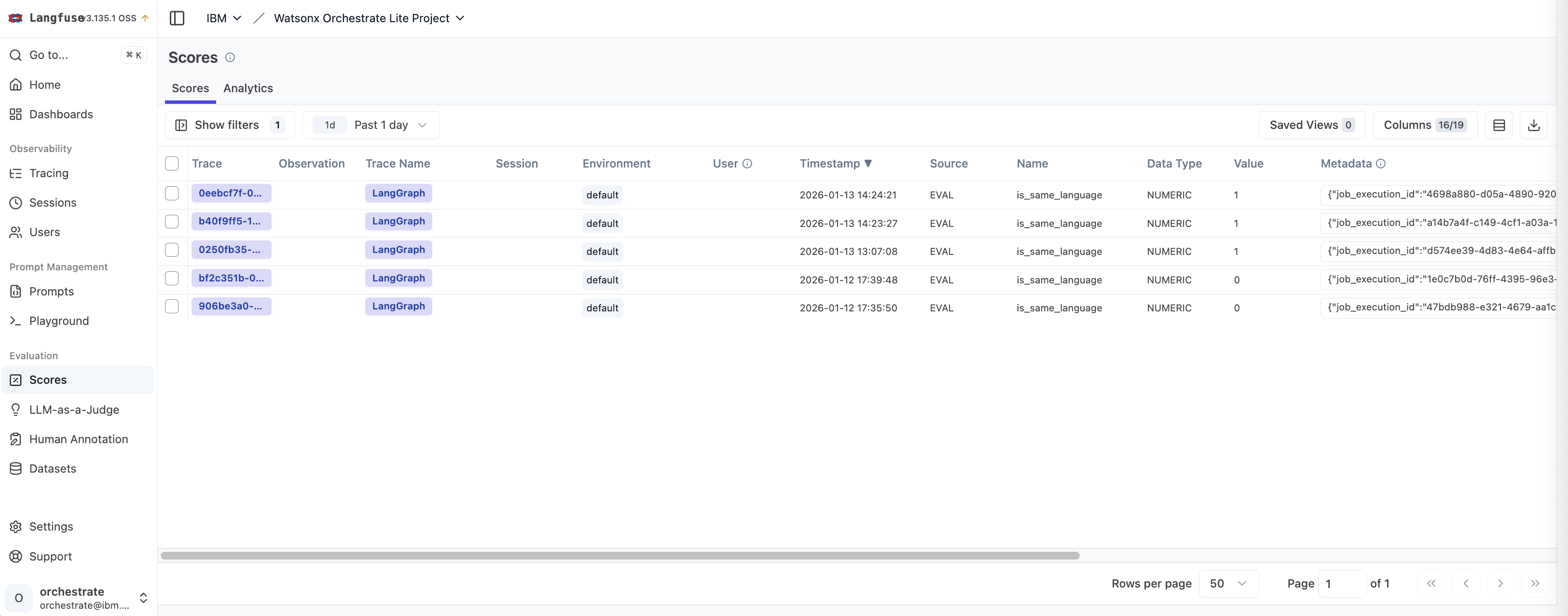
Alternatively, the scores are displayed separately under ‘Scores’.
watsonx Orchestrate
Watsonx Orchestrate is IBM’s platform to build and run multi-agent enterprise systems. It uses Langfuse for observability via OpenTelemetry.
As part of the watsonx Orchestrate ADK (Agent Development Kit) there is a framework to evaluate the quality of agents.
The results of the evaluations can be stored in Langfuse.

Next Steps
To find out more, check out the following resources: