
Training Foundation Models is expensive. Techniques like Prompt Engineering address this by freezing the models and providing context in prompts to optimize results at the expense of losing performance compared to retraining models. New techniques like Prompt Tuning and Multi-task Prompt Tuning are evolving to address this.
My blog Introduction to Prompt Tuning explains the differences between three different ways to customize pretrained foundation models to get the best possible results:
- Fine Tuning
- Prompt Tuning
- Prompt Engineering
The key difference between Fine Tuning and Prompt Tuning is that for Prompt Tuning the models are frozen which means that their parameters are not modified so that customization is cheaper and faster. Sometimes the differentiation between these two options is fluent. In some cases, all layers of the models are frozen, in other cases only the last layers are retrained.
Prompt Tuning
In 2021 researchers from Google introduced Prompt Tuning. I like especially this chart:
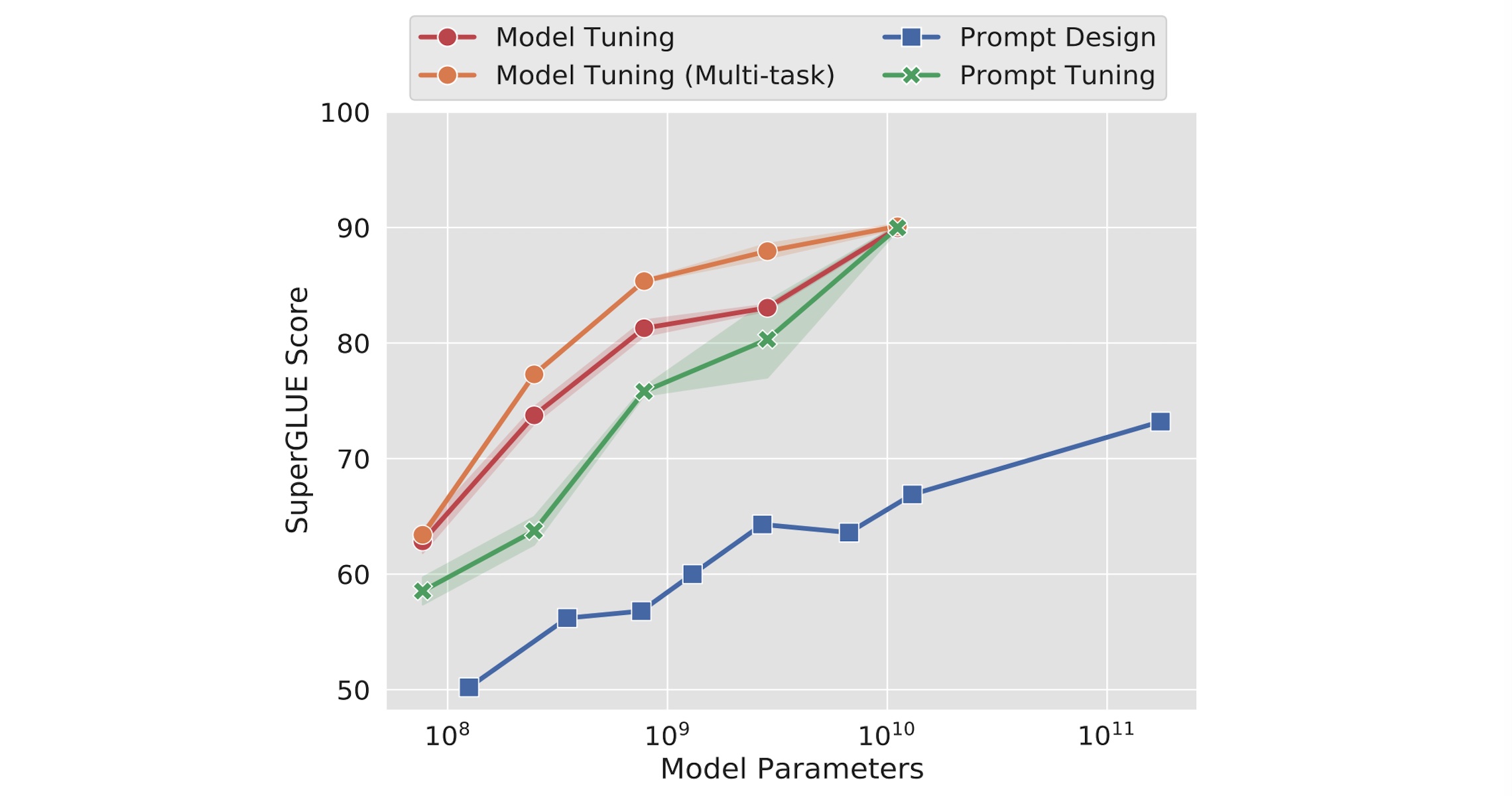
It shows that Prompt Tuning can be as efficient as Fine Tuning (called Model Tuning in the graphic) if the model is large enough. Prompt Engineering (called Prompt Design in the graphic) cannot provide the same performance.
Multi-task Prompt Tuning
IBM Research is also doing incredible work in this space. Read the IBM Research blog What is prompt-tuning?. My highlight is in the middle of the blog where an upcoming paper in announced Multitask Prompt Tuning enables Parameter-efficient Transfer Learning.
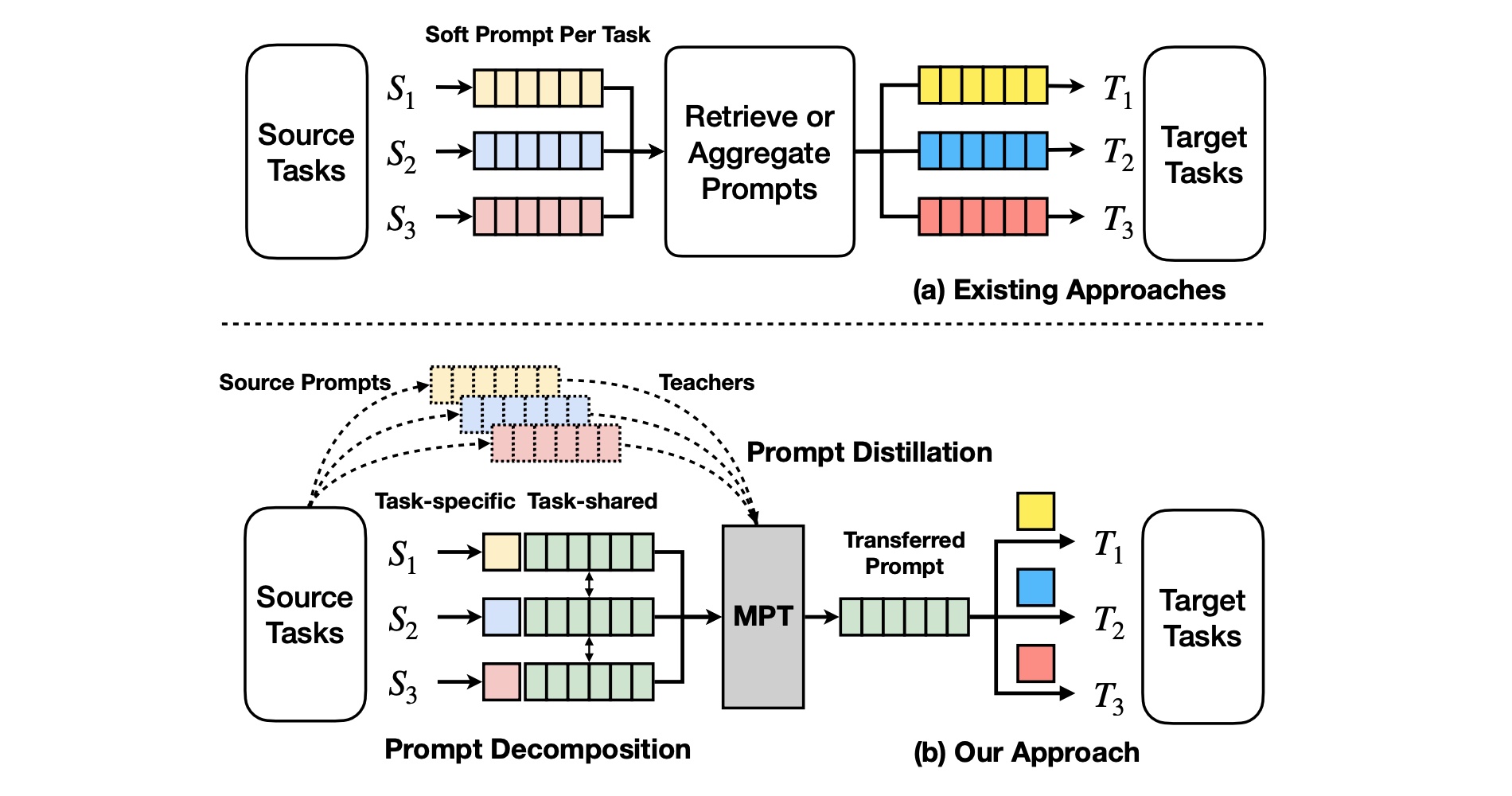
Multi-task Prompt Tuning is an evolution of Prompt Tuning. The graphic at the top of this post describes the main idea.
Instead of retrieving or aggregating source prompts (top), multitask prompt tuning (MPT, bottom) learns a single transferable prompt. The transferable prompt is learned via prompt decomposition and distillation.
And to quote Ramewsar Panda from IBM:
Think of it as applying multi-task transfer learning to prompts. You learn a single prompt that consolidates task-shared knowledge so you can quickly adapt the model.
The results are impressive.
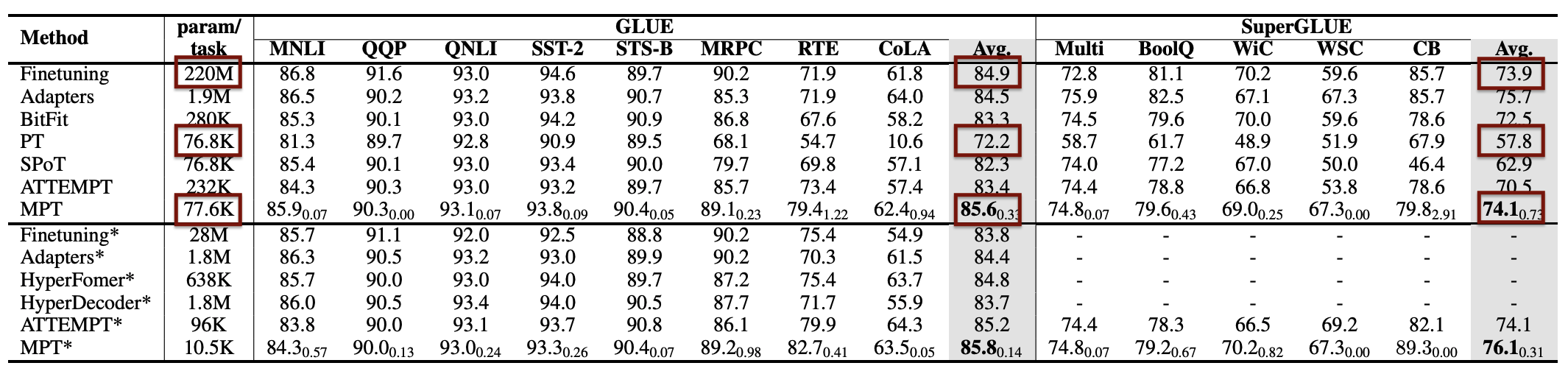
The first line ‘Finetuning’ is just Fine-Tuning as described above. ‘PT’ stands for Prompt Tuning and the original version from Google. ‘MPT’ stands for Multi-task Prompt Tuning which is IBM’s invention in the paper.
As shown for different tests, the performance of Multi-task Prompt Tuning is significantly better than Prompt Tuning. In average it’s even better than Fine Tuning!
Resources
- What is prompt-tuning?
- Multitask Prompt Tuning enables Parameter-efficient Transfer Learning
- Paper: The Power of Scale for Parameter-Efficient Prompt Tuning
- Video: The Power of Scale for Parameter-Efficient Prompt Tuning
- Multitask Prompted Training Enables Zero-Shot Task Generalization
- State-of-the-art Parameter-Efficient Fine-Tuning (PEFT) methods
- Introduction to Prompt Tuning
- Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing