
Good SaaS solutions provide efficient mechanisms how to deploy and operate the same software for multiple clients, but don’t necessarily share the same compute resources because of security reasons.
Over the last months I’ve worked with many companies who want to build SaaS (Software as a Service) to scale their solutions to new markets and to save costs. To address these needs, our team has produced an asset that demonstrates how to build cloud-native applications that can be deployed to multiple clouds and how they can be exposed in multiple marketplaces. Red Hat OpenShift is a perfect technology to address these requirements.
Check out the announcement blog and the SaaS repo.
There are various options how to implement SaaS and there is not the one right way to do so. One of the first questions is how to do persistence and user authentication for different clients. While it might be easier for developers just to add another tenant id column to the database, in many real world scenarios this is not good enough. Often there are requirements to keep the data separate from each other, to be able to archive and restore the data separately and to have separate billing for the used resources.
That is why our SaaS reference architecture uses separate compute resources for containers, databases and authentication services.
Isolated Containers and Compute Resources
The SaaS reference architecture comes with a simple e-commerce sample application. The exact same application can be run on various platforms:
- Serverless via IBM Cloud Code Engine
- Kubernetes via IBM Cloud Kubernetes Service
- OpenShift via IBM Cloud OpenShift Service
The serverless option is an as-easy-as-possible deployment type. Separate projects are used for running the containers in different underlaying Kubernetes namespaces, but the Code Engine runtime is a shared multi-tenancy environment. For better compute isolations Kubernetes namespaces and OpenShift projects can be used. In this case shared clusters are used for all tenants. For the best possible compute isolation different clusters can be used for different tenants.
All variables of the backend and frontend containers have been externalized as suggested by the twelve-factor pattern to make re-use of the same containers possible.
Shared CI/CD
While the compute resources are rather isolated, the application code and the deployment pipelines are shared. This allows for an efficient management of the application for multiple tenants.
For the serverless version of the reference architecture a simple IBM Toolchain on the IBM Cloud is used. The toolchain can be created with just a few clicks and it executes the complete deployment including CI and CD.
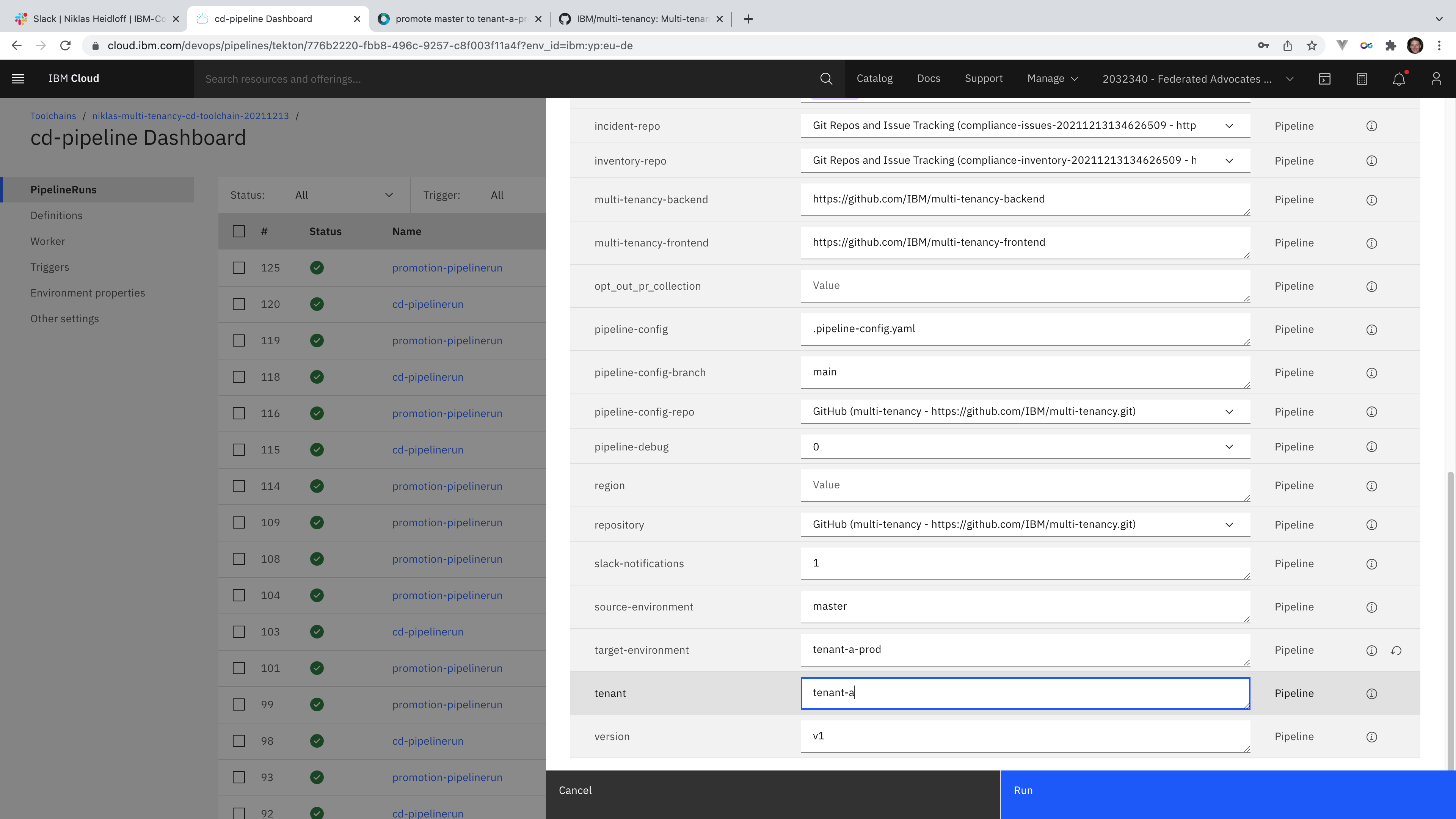
For the Kubernetes and OpenShift versions of the reference architecture a more advanced DevSecOps approach is used which includes separate CI pipelines for the backend and frontend functionality as well as a dedicated CD pipeline for various production environments for different tenants. The following screenshot shows how to run the same CD pipeline for specific tenants.
What’s next?
Take a look at the SaaS reference architecture repo to learn more.
I’ve also planned to blog in more detail about the SaaS repo soon. Keep an eye on this blog.