
watsonx.governance is IBM’s governance offering to manage and monitor (Generative) AI solutions. This post demonstrates how to monitor metrics for models that are not provided by watsonx.ai but hosted on other clouds or on-premises.
Metrics of models that are hosted on watsonx.ai can automatically be handled by watsonx.governance as described in a previous post Generative AI Quality Metrics in watsonx.governance. For models hosted somewhere else and fine-tuned models a feature needs to be used, called ‘Detached Prompt Template’.
Resources:
- Detached Prompt Template Sample Notebook
- Documentation: Generative AI quality evaluations
- Evaluating deployments in spaces
- Video: IBM watsonx.governance: Direct, manage and monitor your Generative AI and ML models, anywhere
- watsonx.governance Sample Notebooks
Scenario
In the following sample a simple model is used which runs inside of a notebook within watsonx.ai (without GPU). While this is not the most typical use case, it demonstrates how this mechanism works in general.
The sample model generates summaries. As metrics standards are leveraged like Rouge and Sentence Similarity.
The following snippets are from a complete sample notebook
Detached Prompt Template
First the detached prompt template is created.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
from ibm_aigov_facts_client import DetachedPromptTemplate, PromptTemplate
detached_information = DetachedPromptTemplate(
prompt_id="detached_prompt",
model_id="google/flan-t5-base",
model_provider="Hugging Face",
model_name="google/flan-t5-base",
model_url="https://huggingface.co/google/flan-t5-base",
prompt_url="prompt_url",
prompt_additional_info={"model_owner": "huggingface"}
)
task_id = "summarization"
name = "External prompt sample (google/flan-t5-base HF) V2.0"
description = "My first detached prompt"
model_id = "google/flan-t5-base"
prompt_variables = {"original_text": ""}
input = "{original_text}"
input_prefix= "Input:"
output_prefix= "Output:"
prompt_template = PromptTemplate(
input=input,
prompt_variables=prompt_variables,
input_prefix=input_prefix,
output_prefix=output_prefix
)
pta_details = facts_client.assets.create_detached_prompt(
model_id=model_id,
task_id=task_id,
name=name,
description=description,
prompt_details=prompt_template,
detached_information=detached_information
)
project_pta_id = pta_details.to_dict()["asset_id"]
...
label_column = "reference_summary"
operational_space_id = "development"
problem_type = "summarization"
input_data_type = "unstructured_text"
monitors = {
"generative_ai_quality": {
"parameters": {
"min_sample_size": 10,
"metrics_configuration": {
}
}
}
}
response = wos_client.monitor_instances.mrm.execute_prompt_setup(
prompt_template_asset_id=project_pta_id,
project_id=PROJECT_ID,
label_column=label_column,
operational_space_id=operational_space_id,
problem_type=problem_type,
input_data_type=input_data_type,
supporting_monitors=monitors,
background_mode=False
)
result = response.result
result.to_dict()
Model Generations
For the evaluations the model is invoked multiple times for each entry in a dataset. Each item needs to include the following information:
- Input text
- Generated output text
- Ground truth output text
The sample notebook doesn’t invoke a real model, but creates some (useless) hardcoded responses. Obviously, this part needs to be replaced with a real implementation.
The ‘evaluate_risk’ Python function invokes OpenScale in watsonx.governance to run the evaluations and store the results.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
test_data_set_name = "data"
content_type = "multipart/form-data"
body = {}
llm_data.to_csv(test_data_path, index=False)
response = wos_client.monitor_instances.mrm.evaluate_risk(
monitor_instance_id=mrm_monitor_instance_id,
test_data_set_name=test_data_set_name,
test_data_path=test_data_path,
content_type=content_type,
body=body,
project_id=PROJECT_ID,
includes_model_output=True,
background_mode=False
)
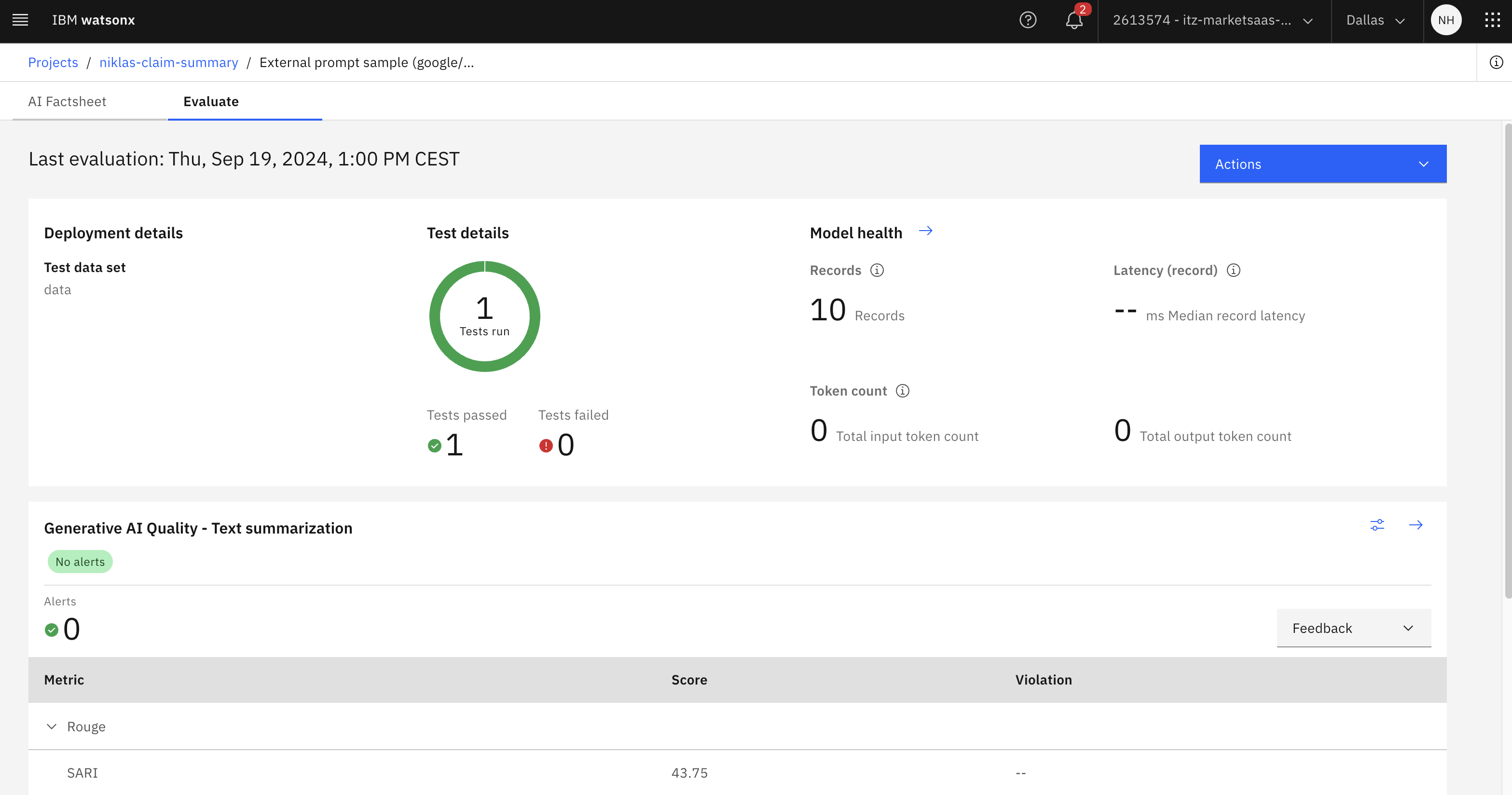
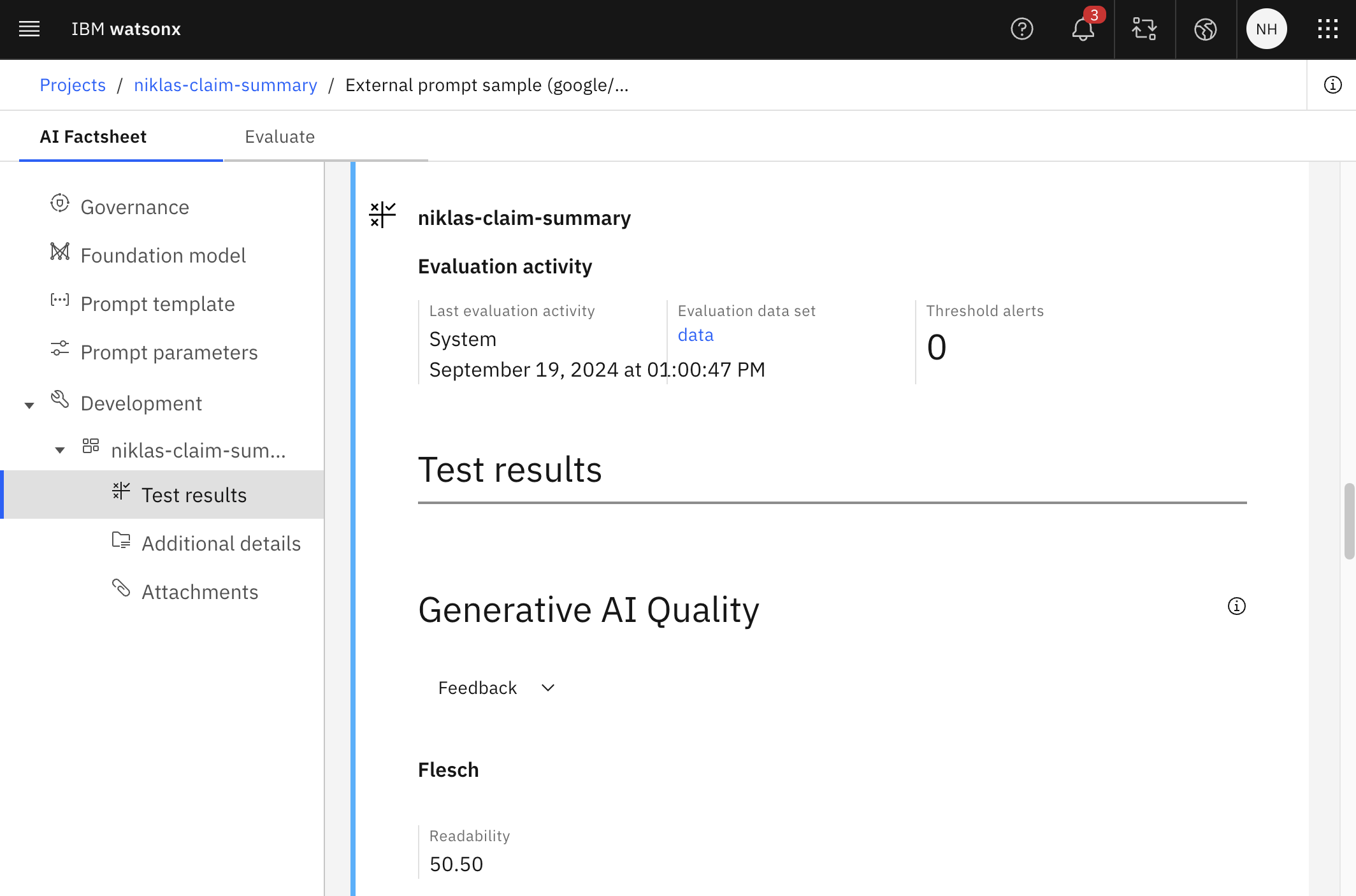
Results
The results of the evaluations can be accessed via API (see notebook). Additionally, they are displayed on the ‘Evaluate’ page (see at the top of this post) and in the ‘Factsheet’.
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.