
With recent MacBook Pro machines and frameworks like MLX and llama.cpp fine-tuning of Large Language Models can be done with local GPUs. This post describes how to use InstructLab which provides an easy way to tune and run models.
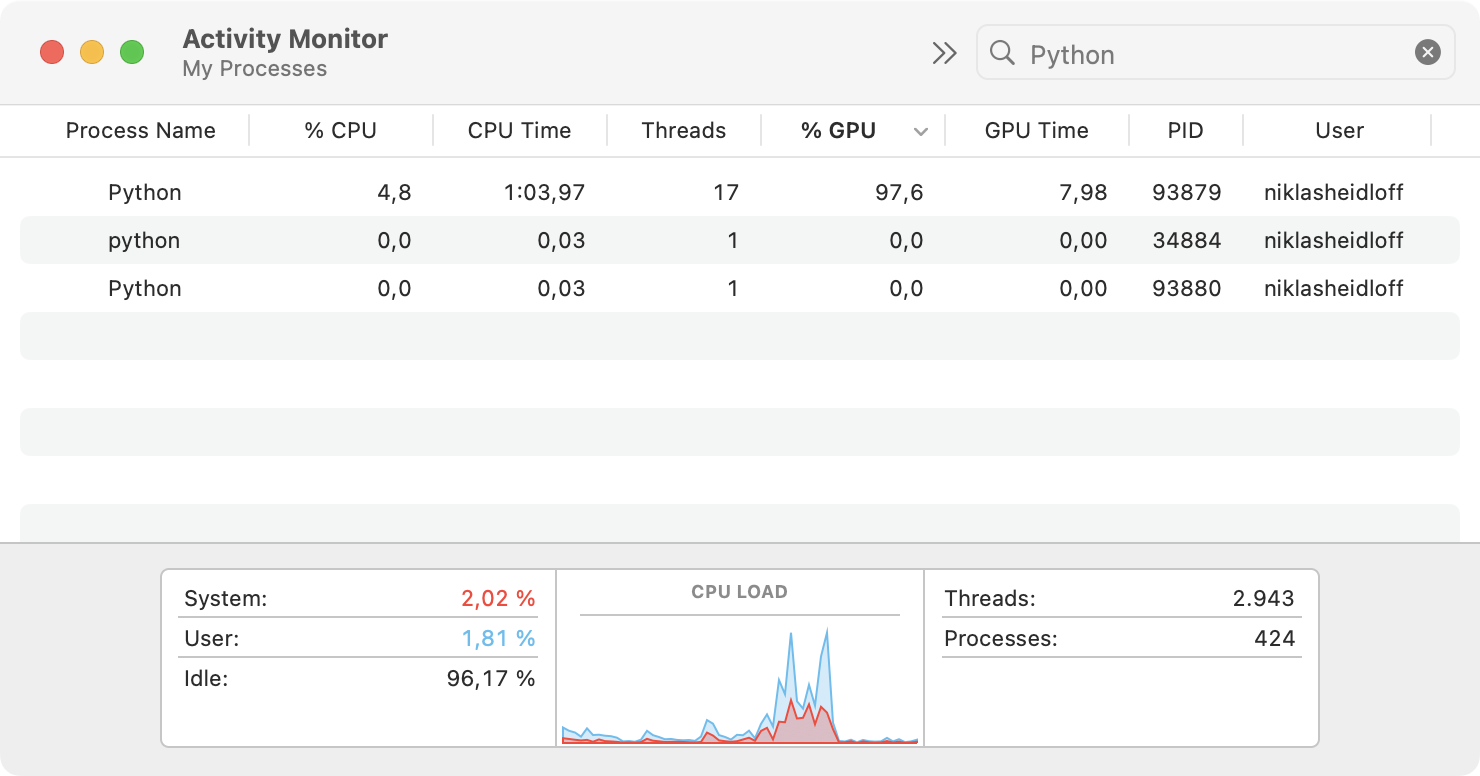
IBM and Red Hat have open sourced a new project called InstructLab. While the main purpose is to generate synthetic data and to fine-tune and align models for several AI tasks using taxonomies, it can also be utilized by developers to fine-tune locally. On my new MacBook Pro M3 with a 18-Core GPU this works very well. As a developer I can test whether my code and my model work in general before more fine-tuning can be done with better GPUs.
The post describes how to tune a model merlinite-7b which is an aligned version of Mistral-7B-v0.1 with Mixtral-8x7B-Instruct as teacher. For the 100 samples the 5 epochs with 100 iterations the fine-tuning takes less than 10 minutes. As example the 7b model is tuned to generate SQL based on natural user input.
- InstructLab
- Running Mistral on CPU via llama.cpp
- Apple MLX
- Fine-tuning LLMs via Hugging Face on IBM Cloud
Load Data
First data needs to be loaded.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from datasets import load_dataset
system_message = """You are an text to SQL query translator. Users will ask you questions in English and you will generate a SQL query based on the provided SCHEMA.
SCHEMA:
{schema}"""
def create_conversation(sample):
return {
"messages": [
{"role": "system", "content": system_message.format(schema=sample["context"])},
{"role": "user", "content": sample["question"]},
{"role": "assistant", "content": sample["answer"]}
]
}
dataset = load_dataset("b-mc2/sql-create-context", split="train")
dataset = dataset.shuffle().select(range(125))
dataset = dataset.map(create_conversation, remove_columns=dataset.features,batched=False)
dataset = dataset.train_test_split(test_size=25/125)
print(dataset["train"][45]["messages"])
dataset["train"].to_json("train_dataset.json", orient="records")
dataset["test"].to_json("test_dataset.json", orient="records")
The data is stored in the typical conversational format.
1
2
3
4
5
6
7
{
"messages":[
{"content":"You are an text to SQL query translator. Users will ask you questions in English and you will generate a SQL query based on the provided SCHEMA.\nSCHEMA:\nCREATE TABLE table_name_71 (tie_no VARCHAR, away_team VARCHAR)","role":"system"},
{"content":"What is Tie No, when Away Team is \"Millwall\"?","role":"user"},
{"content":"SELECT tie_no FROM table_name_71 WHERE away_team = \"millwall\"","role":"assistant"}
]
}
Run the following commands to create 100 items for the tuning and 25 items for the testing.
1
2
3
4
5
6
7
8
9
10
11
12
mkdir fine-tuning-instructlab
cd fine-tuning-instructlab
python3 -m venv venv
source venv/bin/activate
pip install datasets
touch load-data.py
python load-data.py
ls -la
-rw-r--r-- 1 niklasheidloff staff 915 May 14 11:12 load-data.py
-rw-r--r-- 1 niklasheidloff staff 11157 May 14 11:12 test_dataset.json
-rw-r--r-- 1 niklasheidloff staff 47083 May 14 11:12 train_dataset.json
drwxr-xr-x 6 niklasheidloff staff 192 May 14 11:09 venv
Since InstructLab requires another format, the data is converted.
1
2
3
4
5
{
"system": "You are an text to SQL query translator. Users will ask you questions in English and you will generate a SQL query based on the provided SCHEMA.\nSCHEMA:\nCREATE TABLE table_name_71 (tie_no VARCHAR, away_team VARCHAR)",
"user": "What is Tie No, when Away Team is \"Millwall\"?",
"assistant": "SELECT tie_no FROM table_name_71 WHERE away_team = \"millwall\"
}
The snippet shows how to convert the data into the right format.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import json
names=['test', 'train']
for name in names:
with open('./' + name + '_dataset.json', 'r') as json_file:
json_list = list(json_file)
with open('my-data/' + name + '.jsonl', 'w') as outfile:
for json_str in json_list:
result = json.loads(json_str)
message = result['messages']
entry = {
"system": message[0]['content'],
"user": message[1]['content'],
"assistant": message[2]['content']
}
json.dump(entry, outfile)
outfile.write('\n')
These commands create the two files with data in the my-data directory.
1
2
3
4
5
6
7
cd fine-tuning-instructlab
source venv/bin/activate
mkdir my-data
python convert-data.py
ls -la my-data
-rw-r--r-- 1 niklasheidloff staff 10165 May 14 13:00 test.jsonl
-rw-r--r-- 1 niklasheidloff staff 42436 May 14 13:00 train.jsonl
Run Models locally
To run models locally, llama.cpp or InstructLab which uses llama.cpp can be utilized.
InstructLab
In the following example the GGUF quantized version of Mistral 7b is run.
1
2
3
4
5
6
7
8
9
10
11
12
cd fine-tuning-instructlab
source venv/bin/activate
pip install git+https://github.com/instructlab/instructlab.git@stable
ilab init
ilab download --repository TheBloke/Mistral-7B-Instruct-v0.2-GGUF --filename mistral-7b-instruct-v0.2.Q4_K_M.gguf --hf-token xxx
ls -la models
total 8564736
drwxr-xr-x 4 niklasheidloff staff 128 May 14 11:25 .
drwxr-xr-x 9 niklasheidloff staff 288 May 14 11:25 ..
drwxr-xr-x 4 niklasheidloff staff 128 May 14 11:24 .huggingface
-rw-r--r-- 1 niklasheidloff staff 4368439584 May 14 11:25 mistral-7b-instruct-v0.2.Q4_K_M.gguf
ilab serve --model-path models/mistral-7b-instruct-v0.2.Q4_K_M.gguf
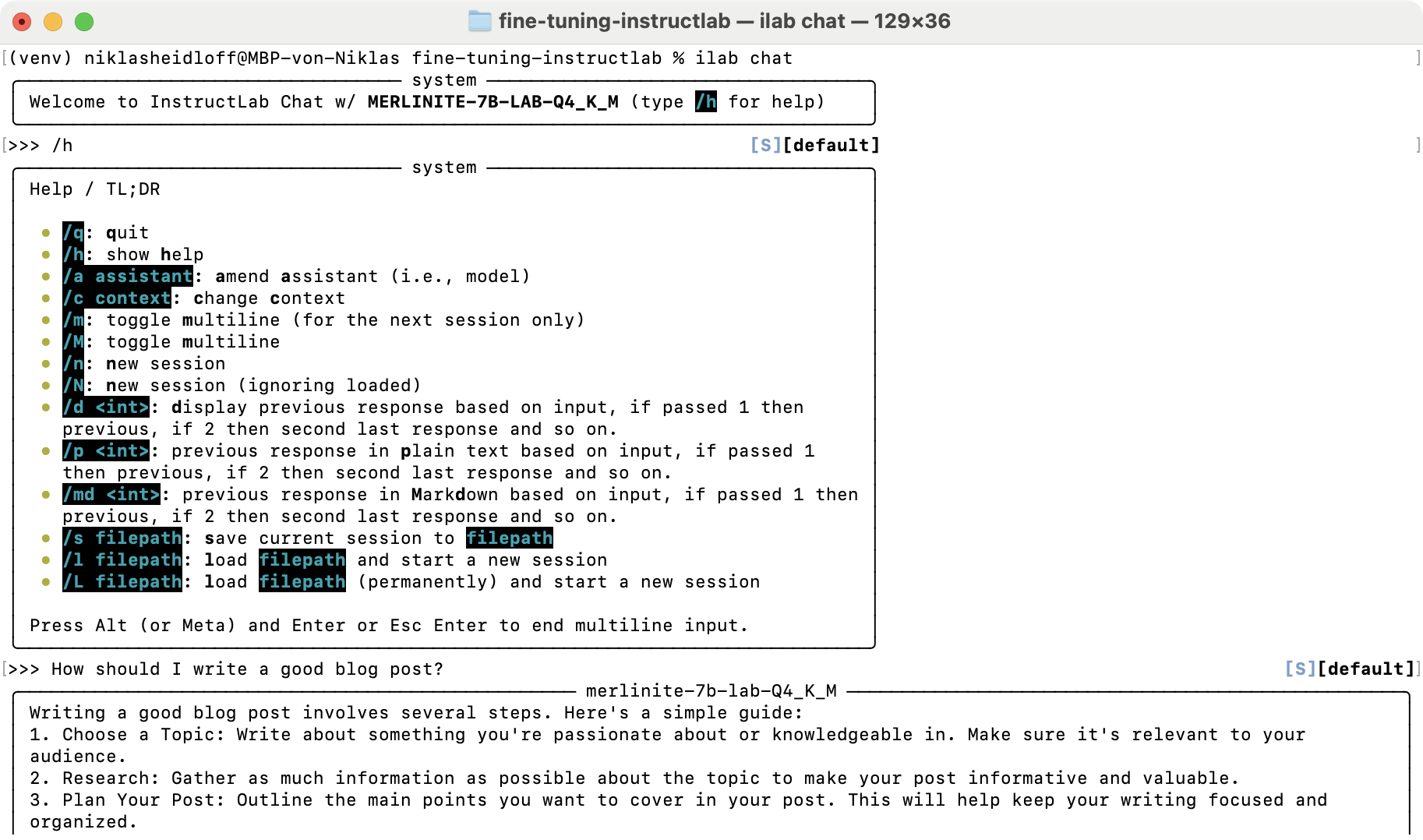
To chat with the model, run the following commands.
1
2
3
cd fine-tuning-instructlab
source venv/bin/activate
ilab chat
llama.cpp
Alternatively, llama.cpp can be invoked directly.
1
2
3
4
5
cd fine-tuning-instructlab
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
./main -m ../models/mistral-7b-instruct-v0.2.Q4_K_M.gguf --temp 0.0 -ins -b 256
Fine-tune Models
This example shows how to fine-tune ibm/merlinite-7b which needs to be downloaded first.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
cd fine-tuning-instructlab
source venv/bin/activate
ilab download
ilab download --repository ibm/merlinite-7b
ls -la models
drwxr-xr-x 4 niklasheidloff staff 128 May 14 11:24 .huggingface
-rw-r--r-- 1 niklasheidloff staff 4368484992 May 14 12:21 merlinite-7b-lab-Q4_K_M.gguf
-rw-r--r-- 1 niklasheidloff staff 4368439584 May 14 11:25 mistral-7b-instruct-v0.2.Q4_K_M.gguf
ls -la models/ibm/merlinite-7b
drwxr-xr-x 4 niklasheidloff staff 128 May 14 13:26 .huggingface
drwxr-xr-x 8 niklasheidloff staff 256 May 14 13:26 Model Card for Merlinite 7b 28cc0b72cf574a4a828140d3539ede4a
-rw-r--r-- 1 niklasheidloff staff 8076 May 14 13:26 README.md
-rw-r--r-- 1 niklasheidloff staff 119 May 14 13:26 added_tokens.json
-rw-r--r-- 1 niklasheidloff staff 735 May 14 13:26 config.json
-rw-r--r-- 1 niklasheidloff staff 136 May 14 13:26 generation_config.json
-rw-r--r-- 1 niklasheidloff staff 4943227872 May 14 13:30 model-00001-of-00003.safetensors
-rw-r--r-- 1 niklasheidloff staff 4999819336 May 14 13:30 model-00002-of-00003.safetensors
-rw-r--r-- 1 niklasheidloff staff 4540581880 May 14 13:31 model-00003-of-00003.safetensors
-rw-r--r-- 1 niklasheidloff staff 23950 May 14 13:26 model.safetensors.index.json
-rw-r--r-- 1 niklasheidloff staff 201367 May 14 13:26 paper.pdf
-rw-r--r-- 1 niklasheidloff staff 670 May 14 13:26 special_tokens_map.json
-rw-r--r-- 1 niklasheidloff staff 1795802 May 14 13:26 tokenizer.json
-rw-r--r-- 1 niklasheidloff staff 493443 May 14 13:26 tokenizer.model
-rw-r--r-- 1 niklasheidloff staff 1961 May 14 13:26 tokenizer_config.json
Next the actual fine-tuning process is started. On my M3 this takes less than 10 minutes.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
cd fine-tuning-instructlab
source venv/bin/activate
ilab train --input-dir my-data --local --model-dir models/ibm/merlinite-7b
[INFO] Loading
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
dtype=mlx.core.float16
[INFO] Quantizing
Using model_type='mistral'
Loading pretrained model
Using model_type='mistral'
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Total parameters 1244.079M
Trainable parameters 1.704M
Loading datasets
Training
Epoch 1: Iter 1: Val loss 4.095, Val took 9.267s
Iter 010: Train loss 3.123, It/sec 0.381, Tokens/sec 153.851
...
Epoch 5: Iter 100: Val loss 0.882, Val took 9.106s
Iter 100: Saved adapter weights to models-ibm-merlinite-7b-mlx-q/adapters-100.npz.
ls -la models-ibm-merlinite-7b-mlx-q
-rw-r--r-- 1 niklasheidloff staff 6832790 May 14 15:11 adapters-010.npz
-rw-r--r-- 1 niklasheidloff staff 6832790 May 14 15:12 adapters-020.npz
-rw-r--r-- 1 niklasheidloff staff 6832790 May 14 15:12 adapters-030.npz
-rw-r--r-- 1 niklasheidloff staff 6832790 May 14 15:13 adapters-040.npz
-rw-r--r-- 1 niklasheidloff staff 6832790 May 14 15:14 adapters-050.npz
-rw-r--r-- 1 niklasheidloff staff 6832790 May 14 15:14 adapters-060.npz
-rw-r--r-- 1 niklasheidloff staff 6832790 May 14 15:15 adapters-070.npz
-rw-r--r-- 1 niklasheidloff staff 6832790 May 14 15:15 adapters-080.npz
-rw-r--r-- 1 niklasheidloff staff 6832790 May 14 15:16 adapters-090.npz
-rw-r--r-- 1 niklasheidloff staff 6832790 May 14 15:17 adapters-100.npz
-rw-r--r-- 1 niklasheidloff staff 6832790 May 14 15:17 adapters.npz
-rw-r--r-- 1 niklasheidloff staff 119 May 14 15:10 added_tokens.json
-rw-r--r-- 1 niklasheidloff staff 2272 May 14 15:10 config.json
-rw-r--r-- 1 niklasheidloff staff 4262441012 May 14 15:10 model.safetensors
-rw-r--r-- 1 niklasheidloff staff 670 May 14 15:10 special_tokens_map.json
-rw-r--r-- 1 niklasheidloff staff 1795802 May 14 15:10 tokenizer.json
-rw-r--r-- 1 niklasheidloff staff 493443 May 14 15:10 tokenizer.model
-rw-r--r-- 1 niklasheidloff staff 1961 May 14 15:10 tokenizer_config.json
Test Models
InstructLab comes with a convenient way to compare the out of the box responses with the responses from the fine-tuned model by running the tests in the my-data folder against both models.
1
2
3
4
5
6
7
8
9
cd fine-tuning-instructlab
source venv/bin/activate
ilab test --data-dir my-data --model-dir models/ibm/merlinite-7b
...
user prompt: Who is the bachelorette of the season that premiered on May 24, 2010?
expected output: SELECT bachelorette FROM table_name_37 WHERE premiered = "may 24, 2010"
Generating
==========
SELECT bachelorette FROM table_name_37 WHERE premiered = "May 24, 2010"
The model can also be served with InstructLab or llama.cpp. In this case it can be quanitzed first.
1
2
3
4
5
6
7
8
9
10
11
12
13
cd fine-tuning-instructlab
source venv/bin/activate
ilab convert --model-dir models-ibm-merlinite-7b-mlx-q
ls -la models-ibm-merlinite-7b-mlx-q-fused-pt
-rw-r--r-- 1 niklasheidloff staff 119 May 14 17:46 added_tokens.json
-rw-r--r-- 1 niklasheidloff staff 2211 May 14 17:46 config.json
-rw-r--r-- 1 niklasheidloff staff 4368484544 May 14 17:47 ggml-model-Q4_K_M.gguf
-rw-r--r-- 1 niklasheidloff staff 14484862880 May 14 17:47 ggml-model-f16.gguf
-rw-r--r-- 1 niklasheidloff staff 14483629008 May 14 17:46 model.safetensors
-rw-r--r-- 1 niklasheidloff staff 670 May 14 17:46 special_tokens_map.json
-rw-r--r-- 1 niklasheidloff staff 1795802 May 14 17:46 tokenizer.json
-rw-r--r-- 1 niklasheidloff staff 493443 May 14 17:46 tokenizer.model
-rw-r--r-- 1 niklasheidloff staff 1961 May 14 17:46 tokenizer_config.json
As other GGUF models InstructLab can serve it now.
1
2
3
cd fine-tuning-instructlab
source venv/bin/activate
ilab serve --model-path models-ibm-merlinite-7b-mlx-q-fused-pt/ggml-model-Q4_K_M.gguf
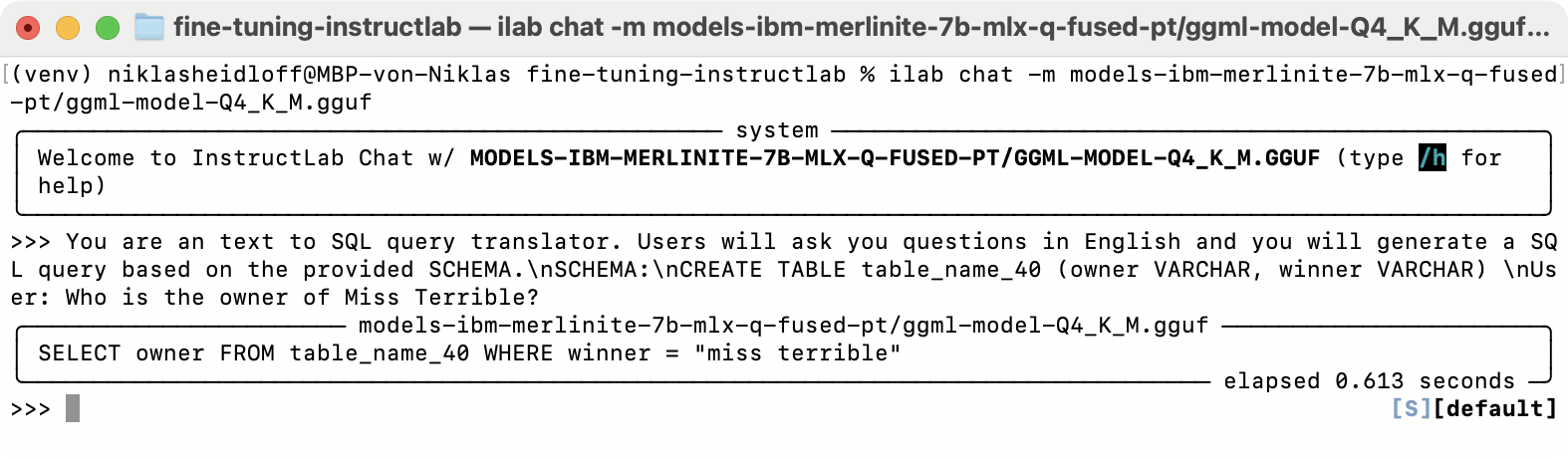
With ilab chat the model can be tested as previously.
1
2
3
cd fine-tuning-instructlab
source venv/bin/activate
ilab chat -m models-ibm-merlinite-7b-mlx-q-fused-pt/ggml-model-Q4_K_M.gguf
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.