
Fine-tuning large language models with instructions is a great technique to customize models efficiently. This post explains briefly how data can be turned into instructions.
In my earlier post Instruction Fine-tuning of Large Language Models I described key concepts of instructions. Some readers had questions how to convert datasets into instructions. For classic ML typically datasets in the following formats are used:
1
2
3
Label, Text
Non-Complaint, Staff very friendly and helpful hotel immaculate
Complaint, My room was dirty and I was afraid to walk barefoot on the floor which looked as if it was not cleaned in weeks White furniture which looked nice in pictures was dirty too ...
1
2
3
4
Example input:
'Anna went to school at University of California Santa Cruz.'
Example output phrases:
'Anna', 'school', 'University of California Santa Cruz'
For decoder-based Large Language Models this works differently, since these models have been trained to predict the next tokens. The trick is to convert the complete dataset into a list of prompts.
Training
The article Extended Guide: Instruction-tune Llama 2 describes a nice sample how to build instructions. The following sample prompt shows how to fine-tune a model to generate an instruction (response below).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
### Instruction:
Use the Input below to create an instruction, which could have been
used to generate the input using an LLM.
### Input:
Hi, I'm writing to request next week, August 1st through August 4th,
off as paid time off.
I have some personal matters to attend ...
Thank you
### Response:
Write an email to my boss that I need next week 08/01 - 08/04 off.
The prompt starts with a (first) instruction to generate a (second) instruction which could have caused the model to generate the input content. For fine-tuning the prompts contain all information including the response. For later inferences the actual responses are generated. Here is the generic version:
1
2
3
4
5
6
7
8
9
### Instruction:
Use the Input below to create an instruction, which could have been
used to generate the input using an LLM.
### Input:
{response}
### Response:
{instruction}
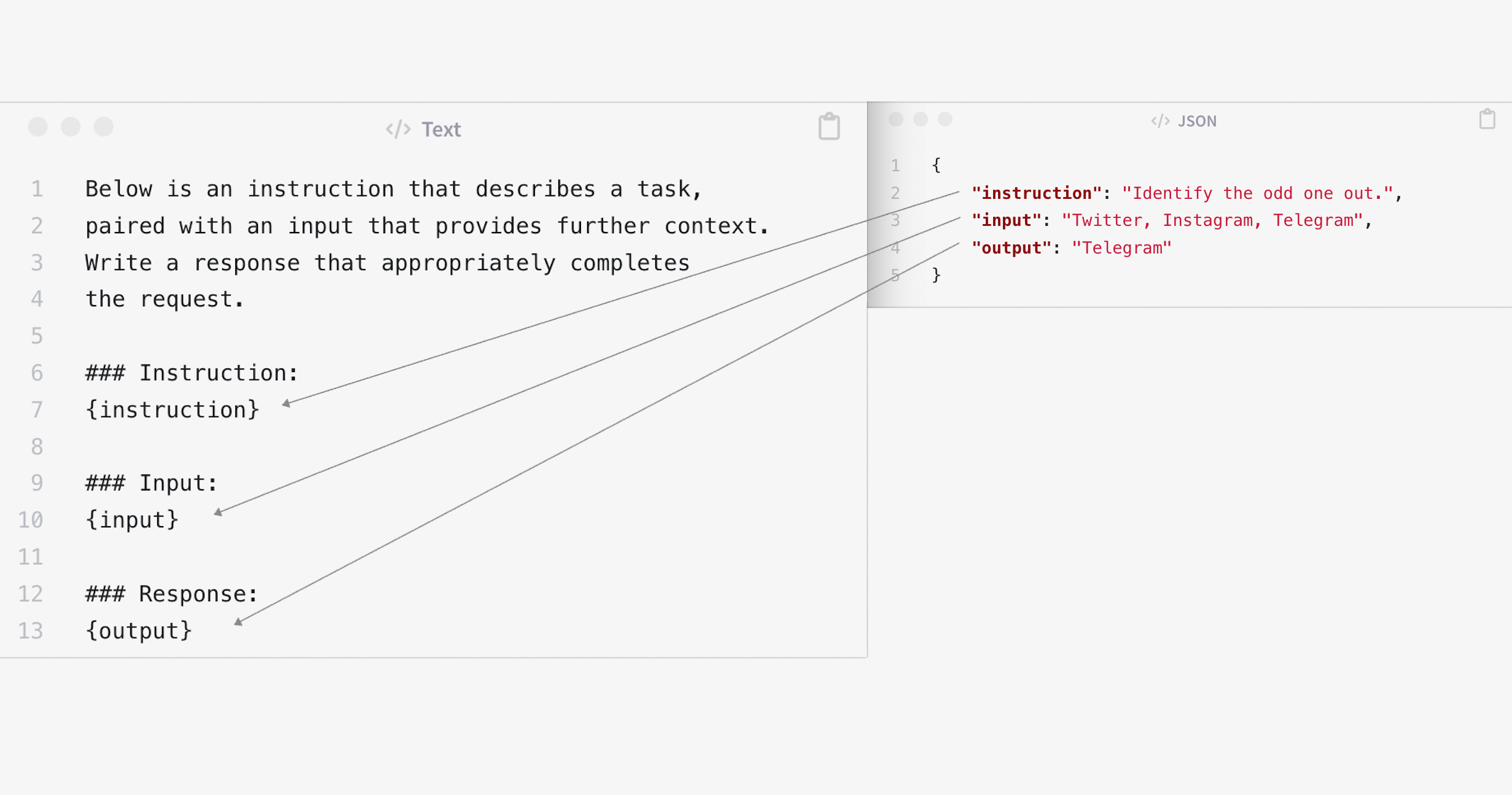
The instruction pattern Alpaca is similar and maybe a little easier to read. The 52k instructions utilize the following format. Context can optionally passed in as input for certain types of instructions.
1
2
3
4
5
6
7
8
9
10
11
12
Below is an instruction that describes a task, paired with an input that
provides further context. Write a response that appropriately completes
the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
{output}
After the complete dataset has been converted to instructions/prompts (see diagram at the top), it is passed as a list of strings to the Hugging Face Supervised Fine-tuning Trainer:
1
2
3
4
5
6
7
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
...
)
trainer.train()
Inference
At runtime prompts are built that follow the same structure that has been used for the fine-tuning. This supports the model to generate text similarly to what it learned during the fine-tuning and it explains why certain prompts work better for certain models.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
model = AutoPeftModelForCausalLM.from_pretrained(
args.output_dir,
...
)
tokenizer = AutoTokenizer.from_pretrained(args.output_dir)
prompt = f"""### Instruction:
Use the Input below to create an instruction, which could have been
used to generate the input using an LLM.
### Input:
Jack Dorsey, Noah Glass, Biz Stone, Evan Williams
### Response:
"""
input_ids = tokenizer(prompt, return_tensors="pt", truncation=True).input_ids.cuda()
outputs = model.generate(input_ids=input_ids, max_new_tokens=100, do_sample=True, top_p=0.9,temperature=0.9)
print(f"Generated instruction:\n{tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0][len(prompt):]}")
> Generated instruction:
> Extract the founders of Twitter from the passage. Display the results in a comma separated format.
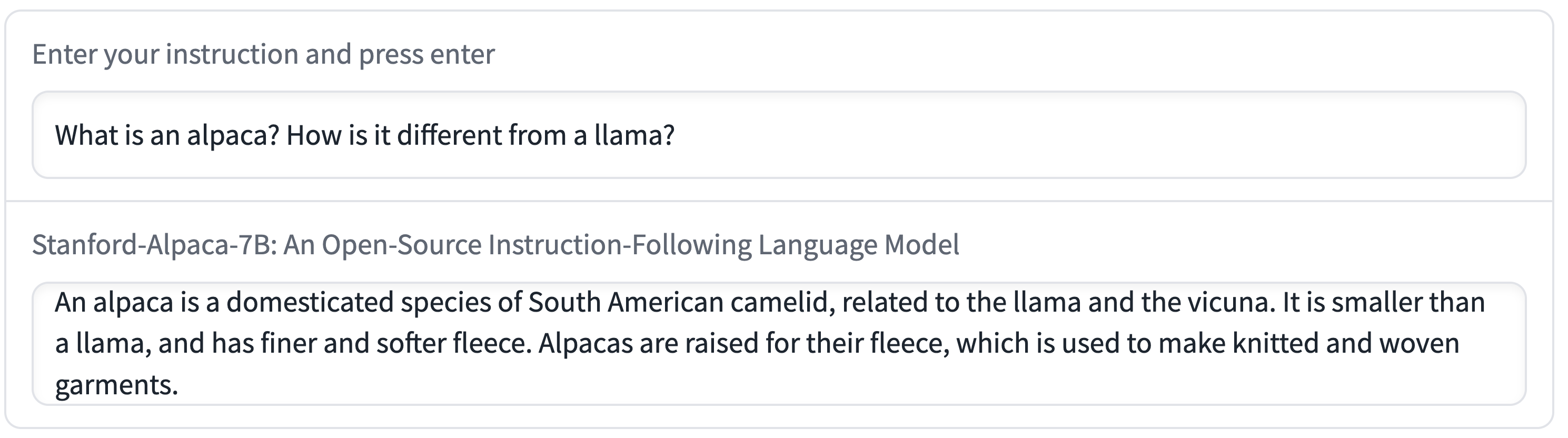
In the following Alpaca sample, it looks like the prompt is “What is an alpaca? How is it different from a llama?”, but this is only the user input. The prompt contains additionally the text from the template above.
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.