
Watson Discovery is an IBM offering to search and analyze information in various types of documents. This post describes how to find patterns in documents via a graphical experience provided by Watson Discovery.
There are several ways to find patterns in texts. Regular expressions are very powerful, but also not trivial to define. Plus they are not really optimal to identify longer repeating expressions in different formats.
Let’s look at an example. As data the publicly available IBM earning report 2018 is used. The goal is to find all occurrences of ‘revenue of …’ with different amounts. In Watson Discovery you can simply select occurrences of this pattern.
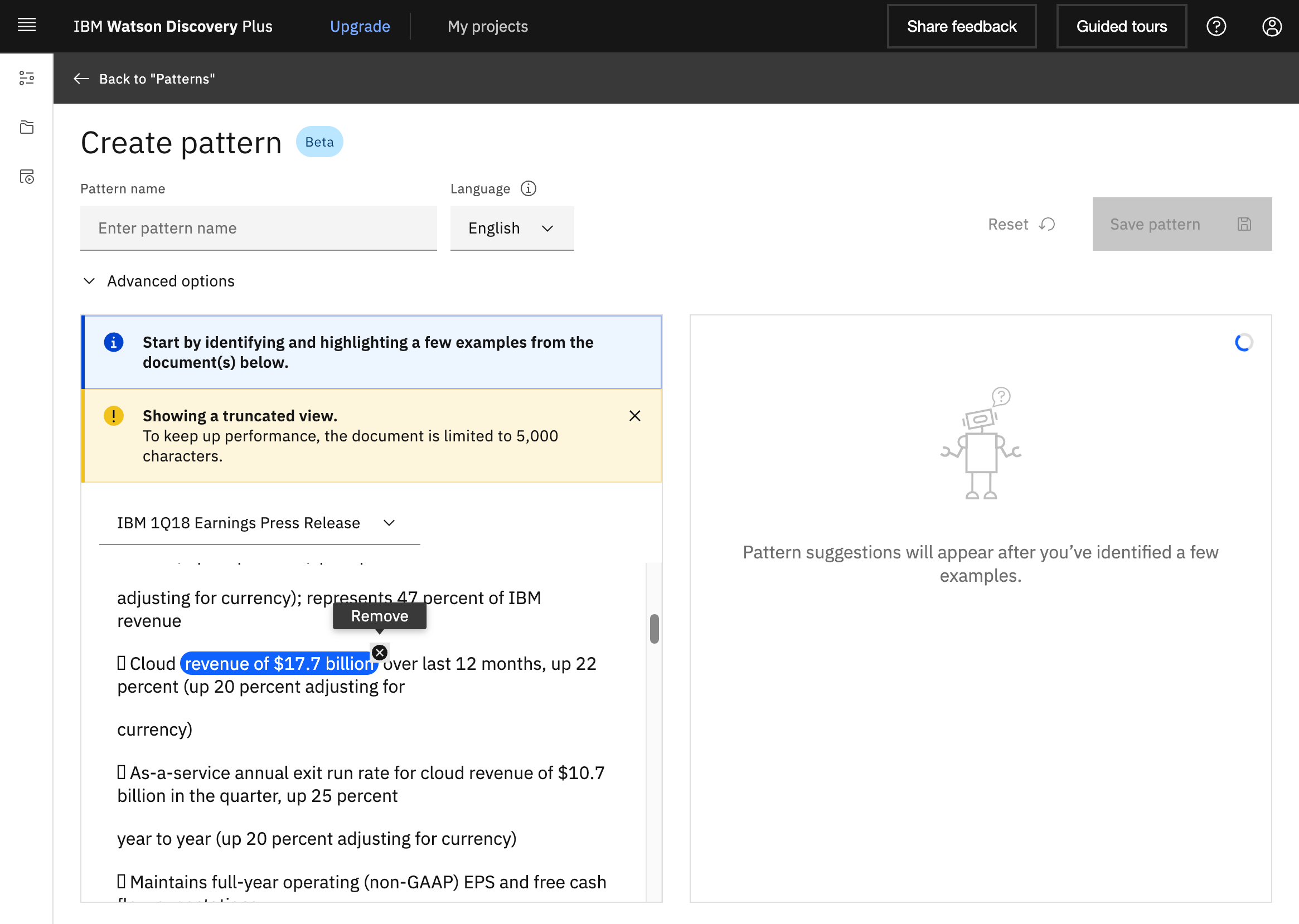
After you’ve selected multiple occurances, Watson starts learning. To improve and validate patterns, Discovery provides a list of further suggestions which can be confirmed or rejected.
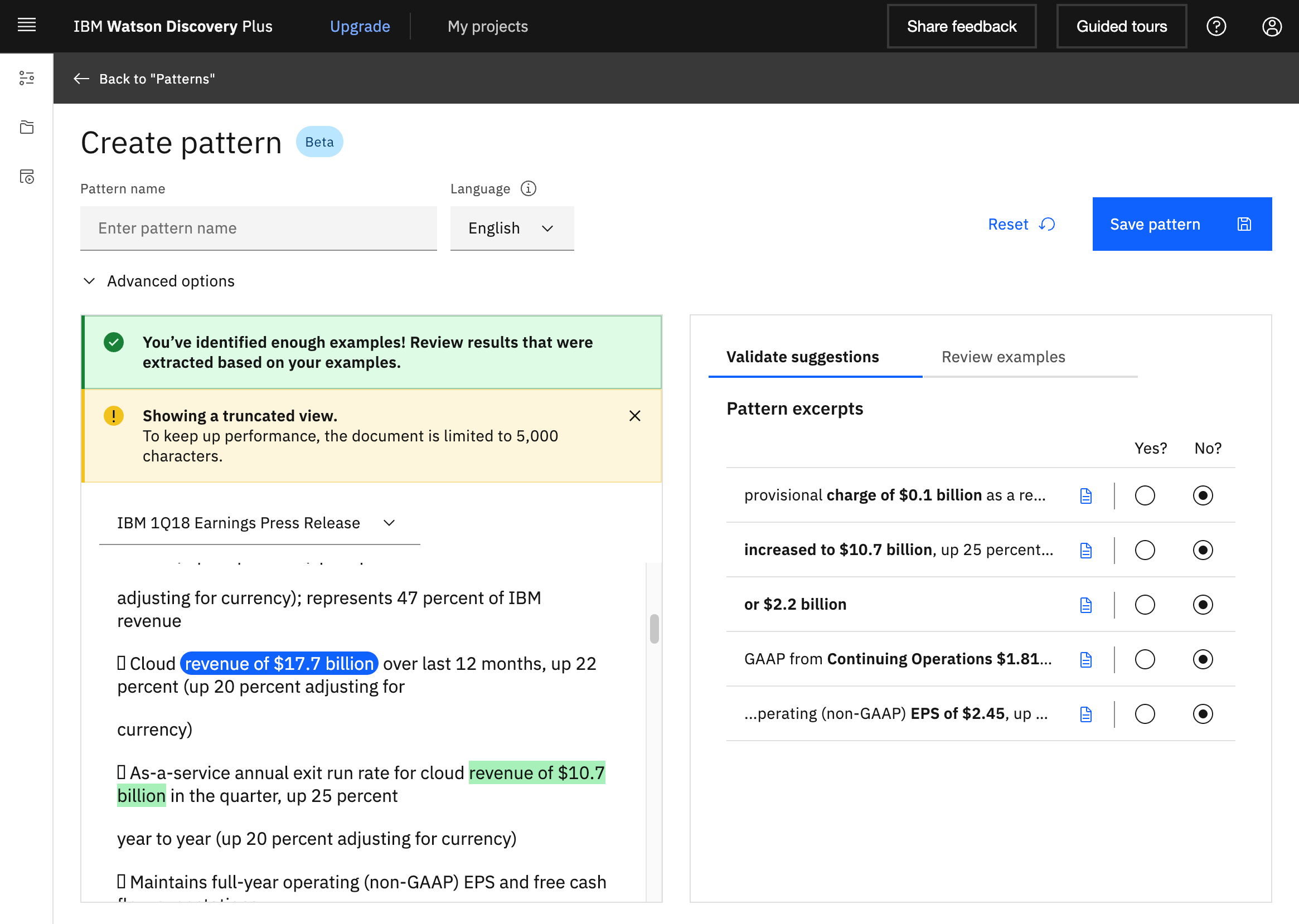
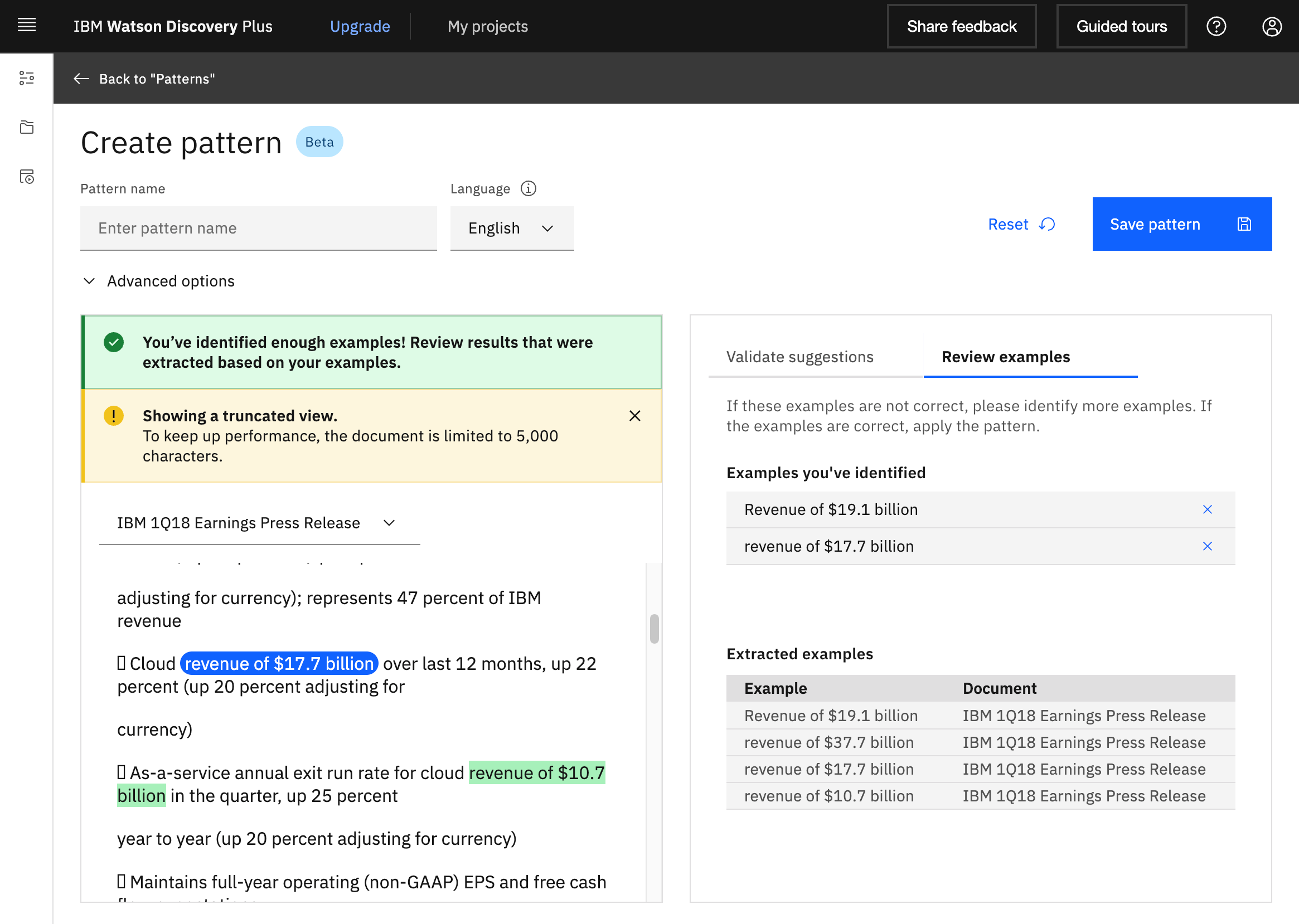
The next screenshot shows how well the pattern recognition works.
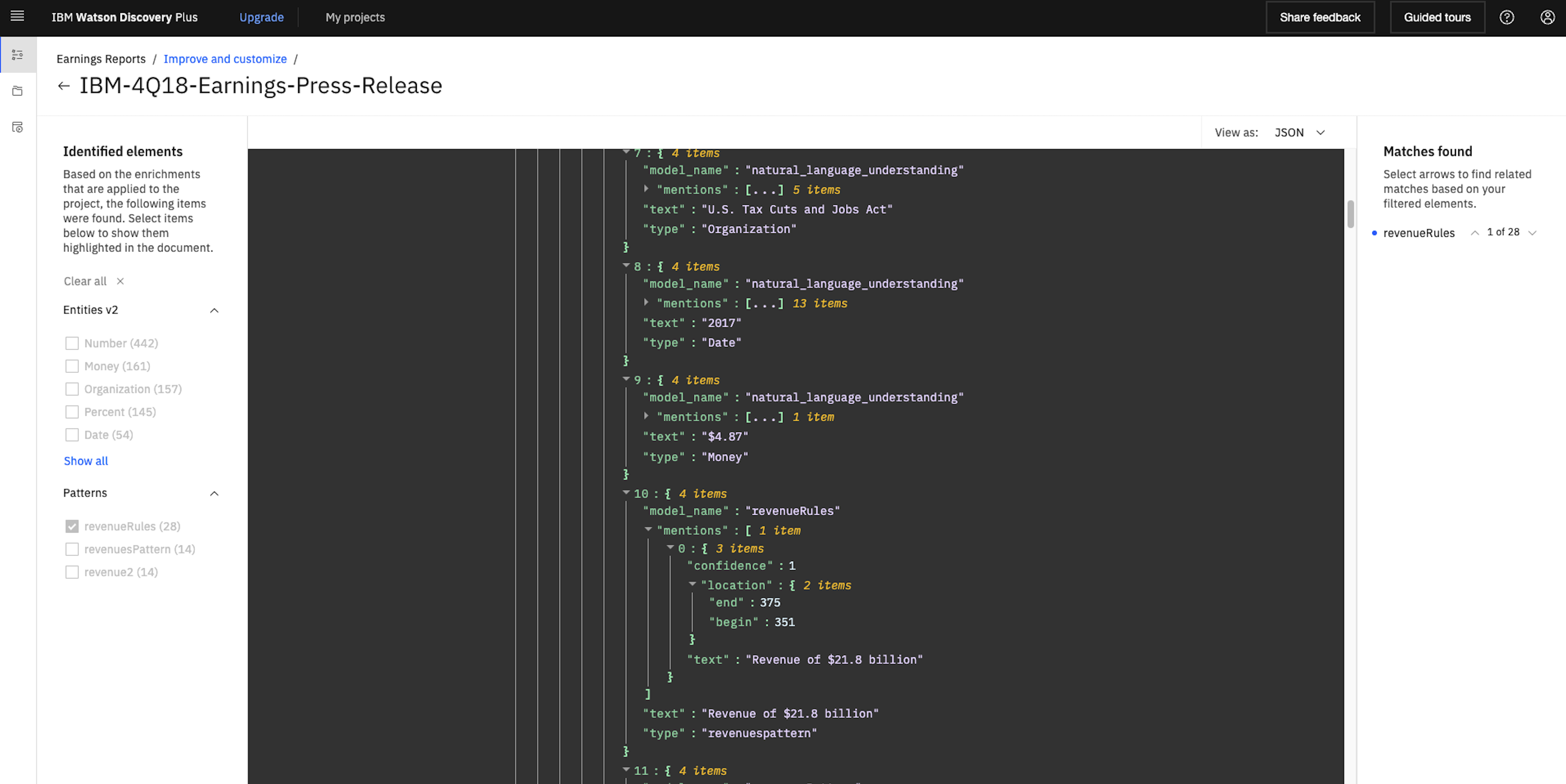
When searching for documents or parts of documents, the found patterns are annotated.
To find out more about this topic, check out the Watson Discovery documentation.