

Docling is an open-source framework to extract information from PDFs, DOCX, tables, images and other document types into structured data for scenarios like Generative AI and agentic applications. This post gives a short introduction of Docling and its main concepts.
The Docling repo describes the core functionality:
- 🗂️ Parsing of multiple document formats incl. PDF, DOCX, PPTX, XLSX, HTML, WAV, MP3, images and more
- 📑 Advanced PDF understanding incl. page layout, reading order, table structure, code, formulas, image classification, and more
- ↪️ Various export formats and options, including Markdown, HTML, DocTags and lossless JSON
- 🔒 Local execution capabilities for sensitive data and air-gapped environments
- 🔍 Extensive OCR support for scanned PDFs and images
- 👓 Support of several Visual Language Models
- 🎙️ Audio support with Automatic Speech Recognition models
- 📤 Structured information extraction (beta)
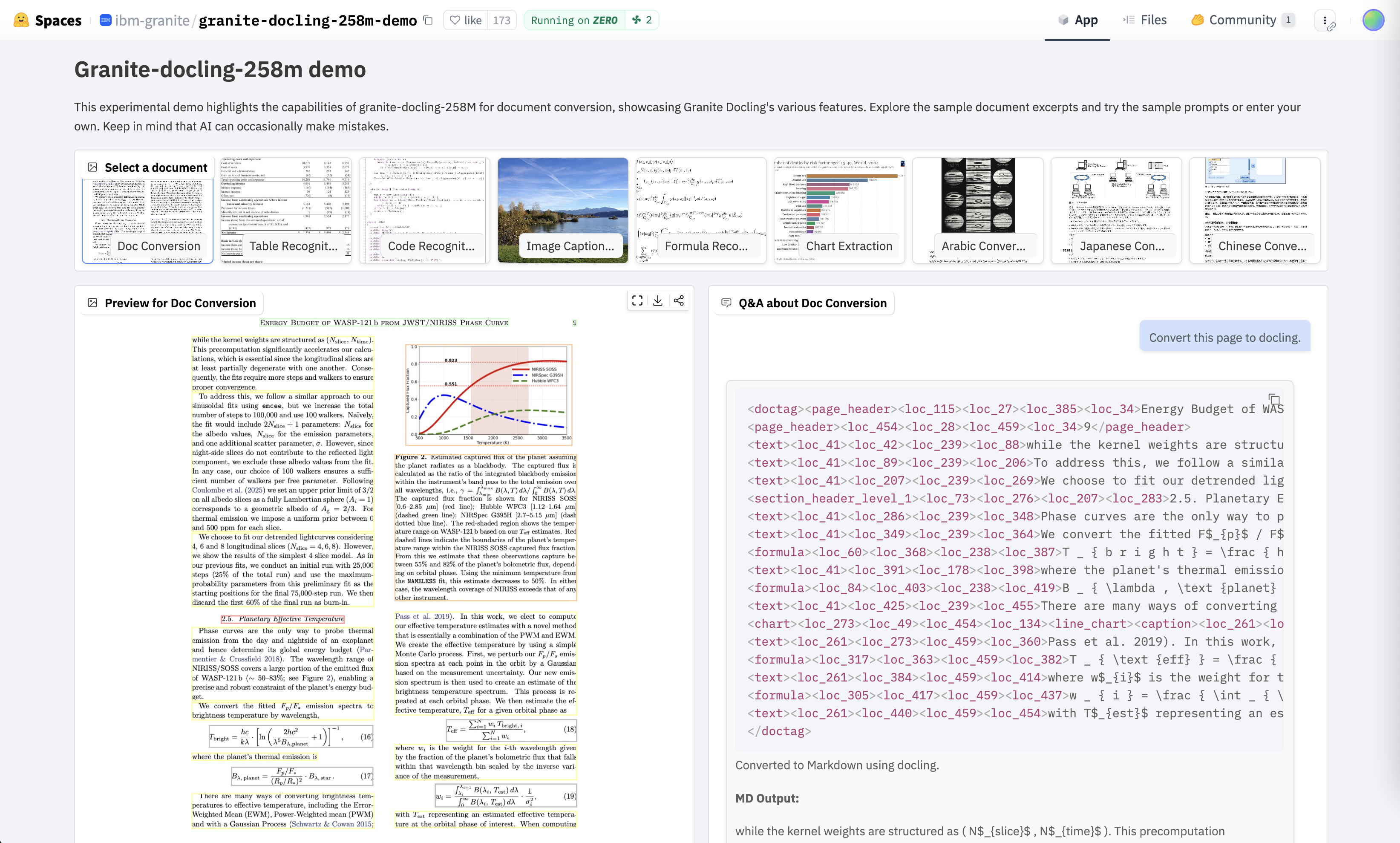
You can try Docling in a Hugging Face space.
Open and Community
IBM has donated the framework to the Linux Foundation. The Docling paper states the differentiation to other frameworks:
Docling stands out as a cost-effective, accurate and transparent open-source library with a permissive MIT license, offering a reliable and flexible solution for document conversion.
Docling has a big and active community and comes with several capabilities to extend its functionality and integrate it in other environments, for example:
- Integrations with frameworks like LangChain and Langflow
- MCP server to integrate Docling as tool in development environments and agentic applications
- Kubernetes operator to deploy Docling as containers on platforms like OpenShift
- Plugins to extend Docling, for example to integrate other OCR engines
Data
The various Docling models have primarily been trained on data, tables, figures and images from PDFs. The article Docling’s Rise describes the importance of these data types.
Together with Hugging Face IBM contributed the FinePDFs dataset - see the article 3-Trillion-Token Dataset Built from PDFs:
Hugging Face has unveiled FinePDFs, the largest publicly available corpus built entirely from PDFs. The dataset spans 475 million documents in 1,733 languages, totaling roughly 3 trillion tokens. […] While most large-scale language model datasets rely on HTML sources such as Common Crawl, PDFs offer unique advantages. They tend to capture higher-quality, domain-specific content, particularly in law, academia, and technical writing.
Unified Document Representation
Docling converts documents into the DoclingDocument format. Documents in the Docling Document format can be converted to plain text, Markdown and HTML for further processing. The intermediate Docling Document format is used to avoid information loss. Additionally, documents can be chunked semantically for RAG scenarios.
DocTags create a clear and structured system of tags and rules that separate text from the document’s structure. This makes things easier for Image-to-Sequence models by reducing confusion. On the other hand, converting directly to formats like HTML or Markdown can be messy — it often loses details, doesn’t clearly show the document’s layout […]. DocTags are integrated with Docling, which allows export to HTML, Markdown, and JSON. These exports can be offloaded to the CPU, reducing token generation overhead and improving efficiency.
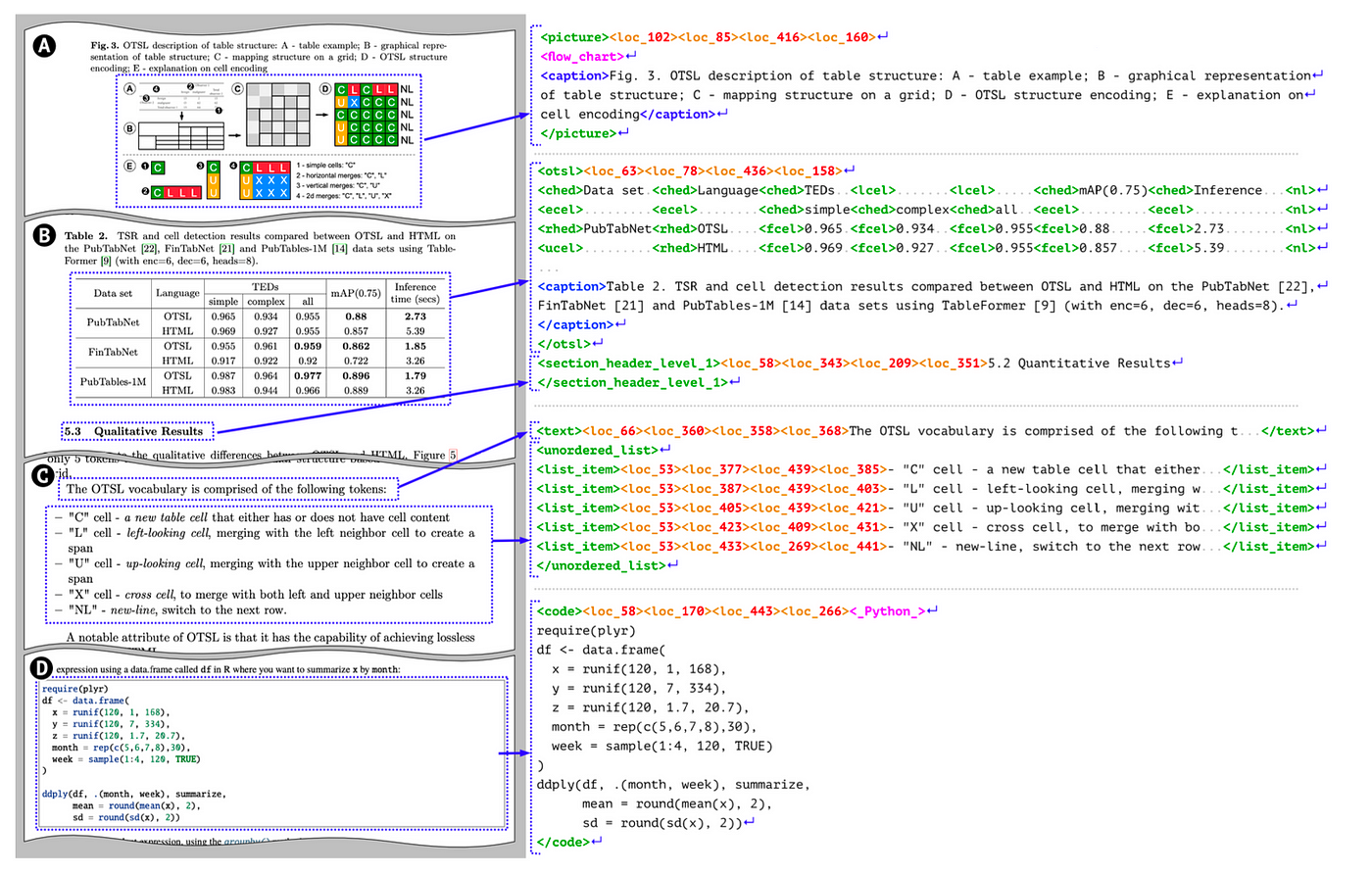
Since Docling is part of the Linux Foundation now, I hope that this format will become a standard for similar tools. Model providers could then use the format for pre-trainings and fine-tuning.
Classic
Docling has two different implementations: 1. Classic and 2. VML (Vision Language Model). The classic version leverages multiple stages to extract information.
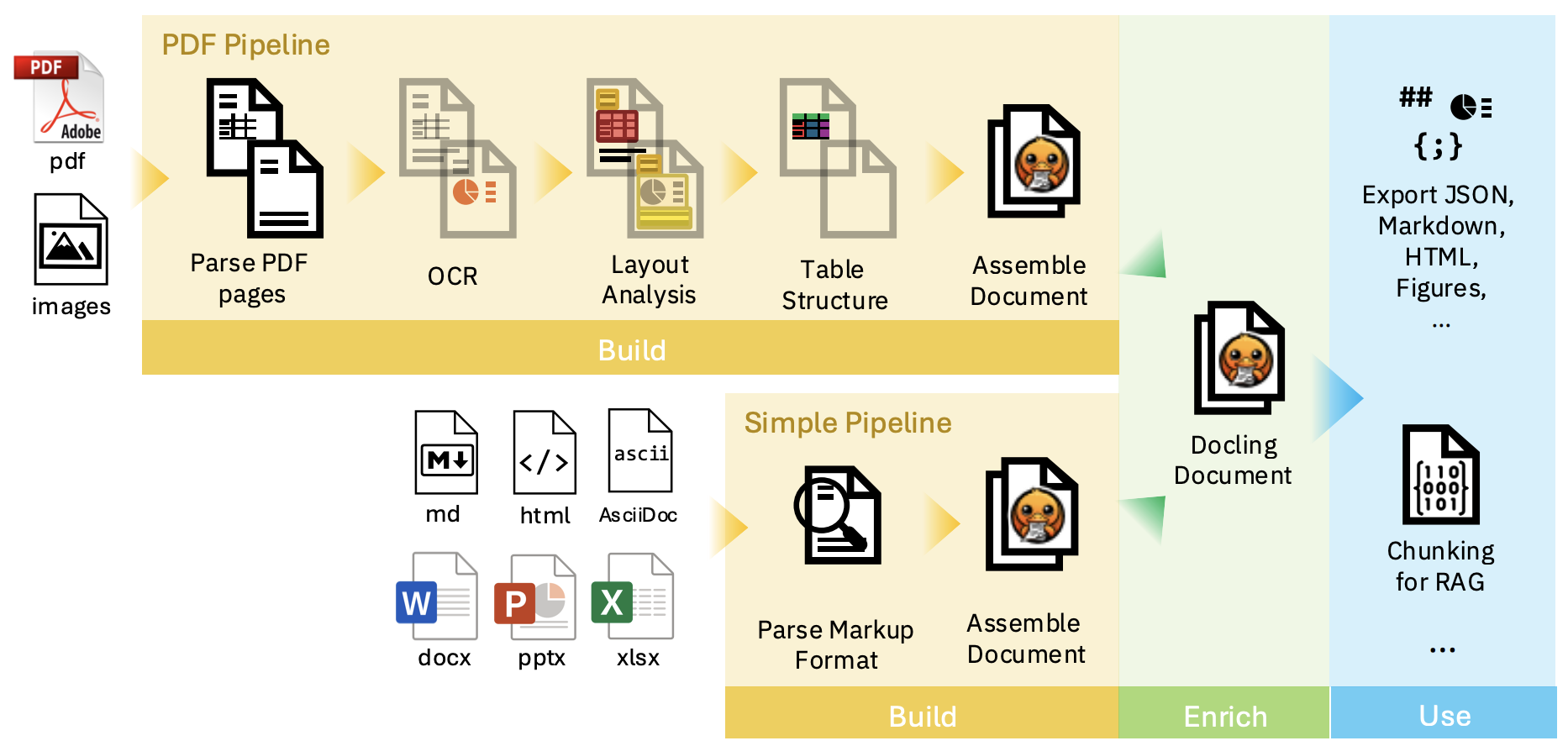
For PDF parsing Docling comes with its own parser, but you can also integrate open-source alternatives. Similarly, different OCR engines can be utilized.
The PDF pipeline applies a sequence of AI models independently on every page of the document to extract features and content, such as layout and table structures. Finally, the results from all pages are aggregated and passed through a post-processing stage, which eventually assembles the DoclingDocument representation.
- Layout Analysis Model
- Table Structure Recognition
- Code Formula Model
- Figure Classifier Model
- Reading Order
VLM
The second implementation is based on a VML (Vision Language Model) and was recently announced. Granite-Docling-258M is an ultra-compact and cutting-edge open-source VLM for converting documents to machine-readable formats while fully preserving their layout, tables, equations, lists and more. It’s now available on Hugging Face through a standard Apache 2.0 license.
Granite-Docling is purpose-built for accurate and efficient document conversion, unlike most VLM-based approaches to optical character recognition (OCR) that aim to adapt large, general-purpose models to the task. Even at an ultra-compact 258M parameters, Granite-Docling’s capabilities rival those of systems several times its size, making it extremely cost-effective.
The following snippet shows how to invoke the two different implementations.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
from docling.datamodel import vlm_model_specs
from docling.datamodel.base_models import InputFormat
from docling.datamodel.pipeline_options import (
VlmPipelineOptions,
)
from docling.document_converter import DocumentConverter, PdfFormatOption
from docling.pipeline.vlm_pipeline import VlmPipeline
source = "https://arxiv.org/pdf/2501.17887"
# 1. Classic implementation
converter = DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(
pipeline_cls=VlmPipeline,
),
}
)
doc = converter.convert(source=source).document
print(doc.export_to_markdown())
# 2. VLM (on Mac via MLX)
pipeline_options = VlmPipelineOptions(
vlm_options=vlm_model_specs.GRANITEDOCLING_MLX,
)
converter = DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(
pipeline_cls=VlmPipeline,
pipeline_options=pipeline_options,
),
}
)
doc = converter.convert(source=source).document
print(doc.export_to_markdown())
Next Steps
To find out more, check out the following resources: