
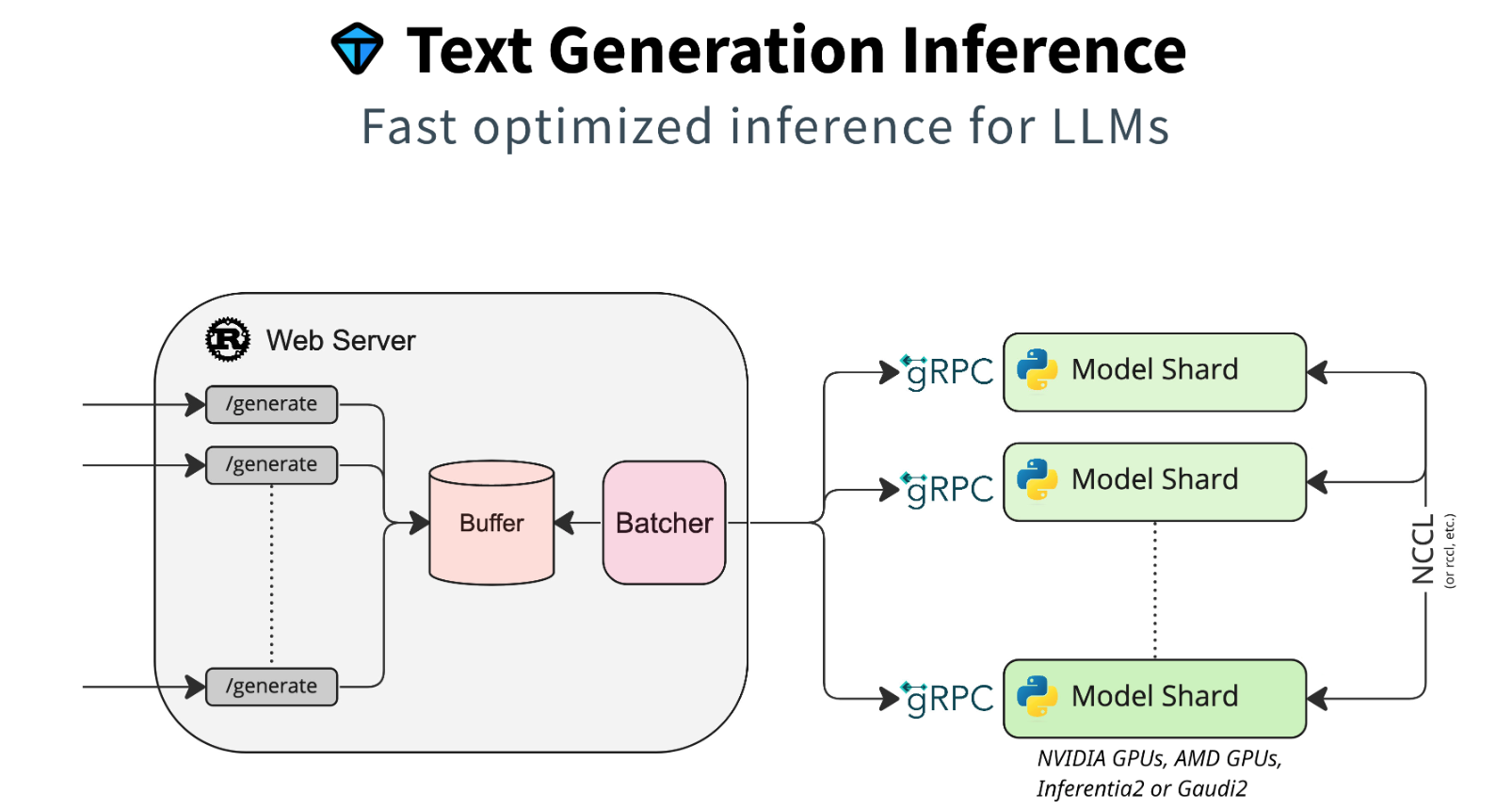
With the Text Generation Inference toolkit from Hugging Face Large Language Models can be hosted efficiently. This post describes how to run open-source models or fine-tuned models on IBM Cloud.
Text Generation Inference (TGI) from Hugging Face “is a toolkit for deploying and serving Large Language Models (LLMs). TGI enables high-performance text generation for the most popular open-source LLMs”.
Below are step by step instructions how to install TGI on virtual servers with V100 GPUs on IBM Cloud. In the easiest case containers can be used which host specific models and provides REST endpoints.
In previous posts I described how to provision V100 GPUs in the IBM Cloud and how to fine-tune your own models:
- Hugging Face Text Generation Inference
- Fine-tuning LLMs via Hugging Face on IBM Cloud
- Deploying a Virtual Server with GPU in the IBM Cloud
- Announcing Mistral 7B
- Hugging Face and IBM working together in open source
Docker
My virtual server runs Ubuntu. To install Docker Engine, follow the documentation.
1
2
3
4
5
6
7
8
9
10
11
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
NVIDIA Container Toolkit
Next the NVIDIA Container Toolkit needs to be installed and configured. This toolkit allows containers to access GPUs.
1
2
3
4
5
6
7
8
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
TGI Server
The TGI container can be launched with open-source models from Hugging Face or local models, for example when models have already been downloaded from Hugging Face or when models have been fine-tuned.
1
2
3
4
5
6
7
8
9
10
11
# Hugging Face model (automatically downloaded)
model=mistralai/Mistral-7B-v0.1
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4 --model-id $model
# Local fine-tuned model
volume=/text-to-sql/output/model
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:latest --model-id /data/mistral-7b-text-to-sql-20240207
# Local Hugging Face model
volume=/root/.cache/huggingface/hub
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:latest --model-id /data/models--mistralai--Mistral-7B-v0.1/snapshots/26bca36bde8333b5d7f72e9ed20ccda6a618af24
Here is some of the output of the container after it has been started and invoked once.
1
2
3
4
5
6
7
8
9
10
11
2024-02-14T06:49:24.783197Z INFO text_generation_launcher: Args { model_id: "/data/models--mistralai--Mistral-7B-v0.1/snapshots/26bca36bde8333b5d7f72e9ed20ccda6a618af24", ...
2024-02-14T06:49:24.783316Z INFO download: text_generation_launcher: Starting download process.
2024-02-14T06:49:27.099268Z INFO text_generation_launcher: Files are already present on the host. Skipping download.
2024-02-14T06:49:27.587880Z INFO download: text_generation_launcher: Successfully downloaded weights.
2024-02-14T06:49:27.588182Z INFO shard-manager: text_generation_launcher: Starting shard rank=0
2024-02-14T06:49:38.479212Z INFO text_generation_launcher: Server started at unix:///tmp/text-generation-server-0
2024-02-14T06:49:38.600975Z INFO text_generation_launcher: Starting Webserver
2024-02-14T06:49:38.688621Z INFO text_generation_router: router/src/main.rs:288: Warming up model
2024-02-14T06:49:40.621798Z INFO text_generation_router: router/src/main.rs:326: Connected
2024-02-14T06:49:51.437631Z INFO generate{parameters=GenerateParameters { best_of: None, temperature: None, repetition_penalty: None, frequency_penalty: None, top_k: None, top_p: None, typical_p: None, do_sample: false, max_new_tokens: Some(14), return_full_text: None, stop: [], truncate: None, watermark: false, details: false, decoder_input_details: false, seed: None, top_n_tokens: None } total_time="611.286748ms" validation_time="754.5µs" queue_time="127.337µs" inference_time="610.405028ms" time_per_token="43.600359ms" seed="None"}: text_generation_router::server: router/src/server.rs:299: Success
TGI Client
TGI provides a REST endpoint. The following Python code shows a simple invocation.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
import requests
prompt = """You are an text to SQL query translator. Users will ask you questions in English and you will generate a SQL query based on the provided SCHEMA.
SCHEMA:
CREATE TABLE [Employee]
(
[EmployeeId] INTEGER NOT NULL,
[LastName] NVARCHAR(20) NOT NULL,
[FirstName] NVARCHAR(20) NOT NULL,
[Title] NVARCHAR(30),
[ReportsTo] INTEGER,
[BirthDate] DATETIME,
[HireDate] DATETIME,
[Address] NVARCHAR(70),
[City] NVARCHAR(40),
[State] NVARCHAR(40),
[Country] NVARCHAR(40),
[PostalCode] NVARCHAR(10),
[Phone] NVARCHAR(24),
[Fax] NVARCHAR(24),
[Email] NVARCHAR(60)
);
QUESTION:
How many employees are there?
ANSWER:
"""
headers = {
"Content-Type": "application/json",
}
data = {
'inputs': prompt,
'parameters': {
'max_new_tokens': 8,
},
}
response = requests.post('http://127.0.0.1:8080/generate', headers=headers, json=data)
print(response.json())
Mistral returns the correct SQL statement.
1
2
python3 test-tgis.py
{'generated_text': 'SELECT COUNT(*) FROM Employee'}
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.