
With the TechZone Toolkit software like OpenShift can be set up in the cloud including custom applications by using automation via Terraform and Argo CD. This article describes how to configure the toolkit or more precisely the solution definitions.
In an earlier blog I explained the toolkit: Introducing IBM’s Toolkit to handle Everything as Code. The toolkit leverages Terrafrom and GitOps and is based on best practices based on IBM experiences in partner and clients projects.
The toolkit module catalog provides 200+ modules to install IBM Software and open source components which can be deployed on clouds like AWS, Azure and IBM Cloud. Solutions are defined in yaml files. The bill of materials contain lists of modules, in this example OpenShift in the IBM Cloud, Argo CD including a GitOps repo, the Watson NLP (natural language processing) container and a custom application.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
apiVersion: cloudnativetoolkit.dev/v1alpha1
kind: BillOfMaterial
metadata:
name: cluster-with-watson-nlp
spec:
modules:
- name: ibm-ocp-vpc
version: v1.16.0
- name: argocd-bootstrap
version: v1.12.0
- name: gitops-repo
alias: gitops_repo
version: v1.22.2
- name: terraform-gitops-ubi
alias: terraform_gitops_ubi
version: v0.0.8
- name: terraform-gitops-watson-nlp
alias: terraform_gitops_watson_nlp
version: v0.0.80
Bill of materials can be and should be shared for different scenarios. To customize them two files are used.
- output/credentials.properties: Contains credentials
- output/bom-name/variables.yaml: Contains all other variables
The following sample shows how to define variables like regions, resource group names, size of the cluster, etc.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
variables:
# overall
- name: region
description: The IBM Cloud region where the instance should be provisioned
value: xxx
- name: resource_group_name
description: The name of the IBM Cloud resource group where the resources should be provisioned
value: xxx
# ocp
- name: worker_count
description: The number of workers that should be provisioned per subnet
value: 2
- name: cluster_flavor
description: The flavor of the worker nodes that will be provisioned
value: bx2.4x16
When ArgoCD is used, a Git token is needed to access the GitOps repo which is stored in credentials.properties. The same mechanism applies for tokens to pull container images from protected registries as well as other credentials.
1
2
3
export TF_VAR_gitops_repo_token=xxx
export TF_VAR_ibmcloud_api_key=xxx
export TF_VAR_terraform_gitops_watson_nlp_registry_credentials=xxx,xxx,xxx
With the toolkit’s CLI the bill of material, the variables and the credentials are converted to Terraform assets in the ‘output/bom-name/terraform’ folder. Be careful when managing this folder with Git to prevent your credentials to be exposed. Note that the generated files are usually not touched.
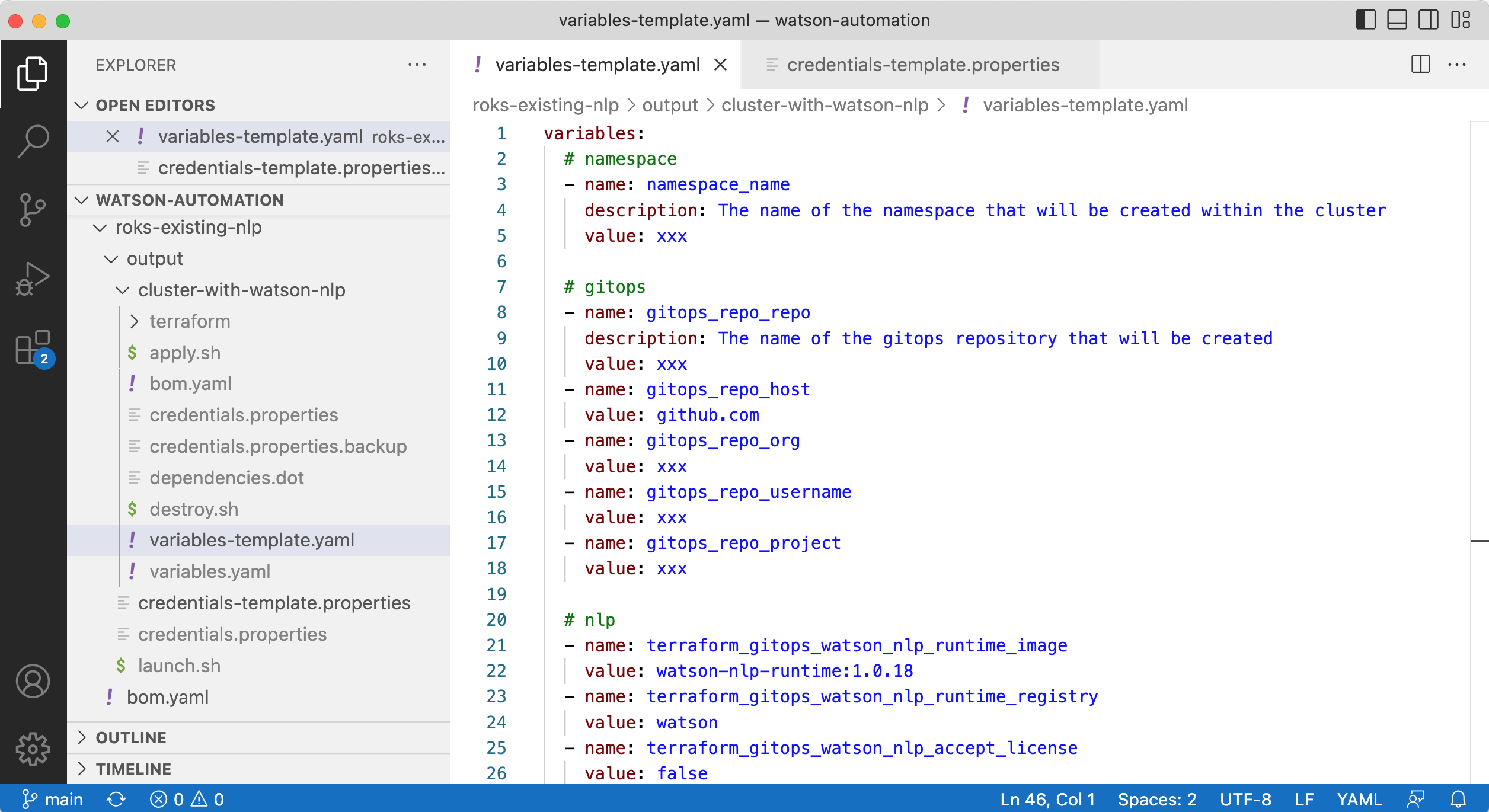
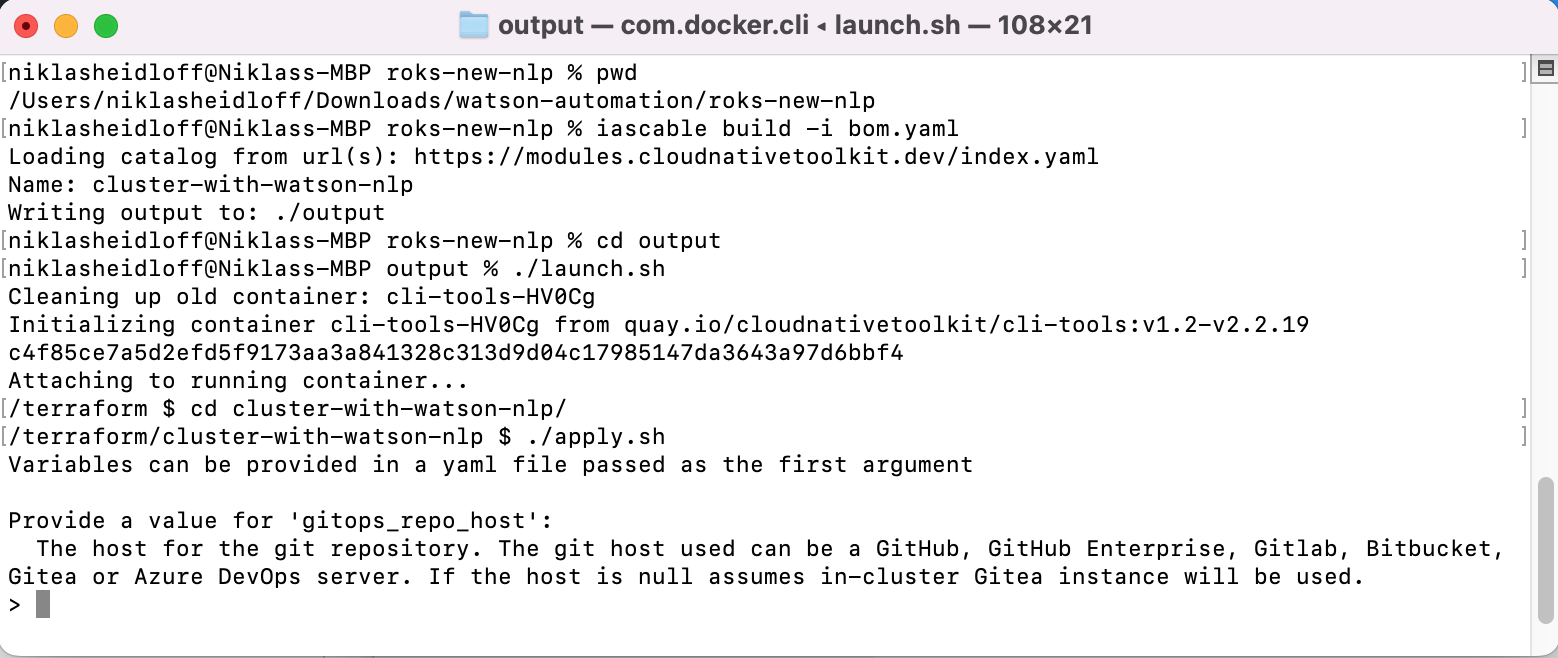
When the variables and credentials are not predefined, CLI users will get prompted to define them when invoking ‘iascable build’.
To find out more about the toolkit, check out the documentation and the sample which deploys OpenShift and Watson NLP.