
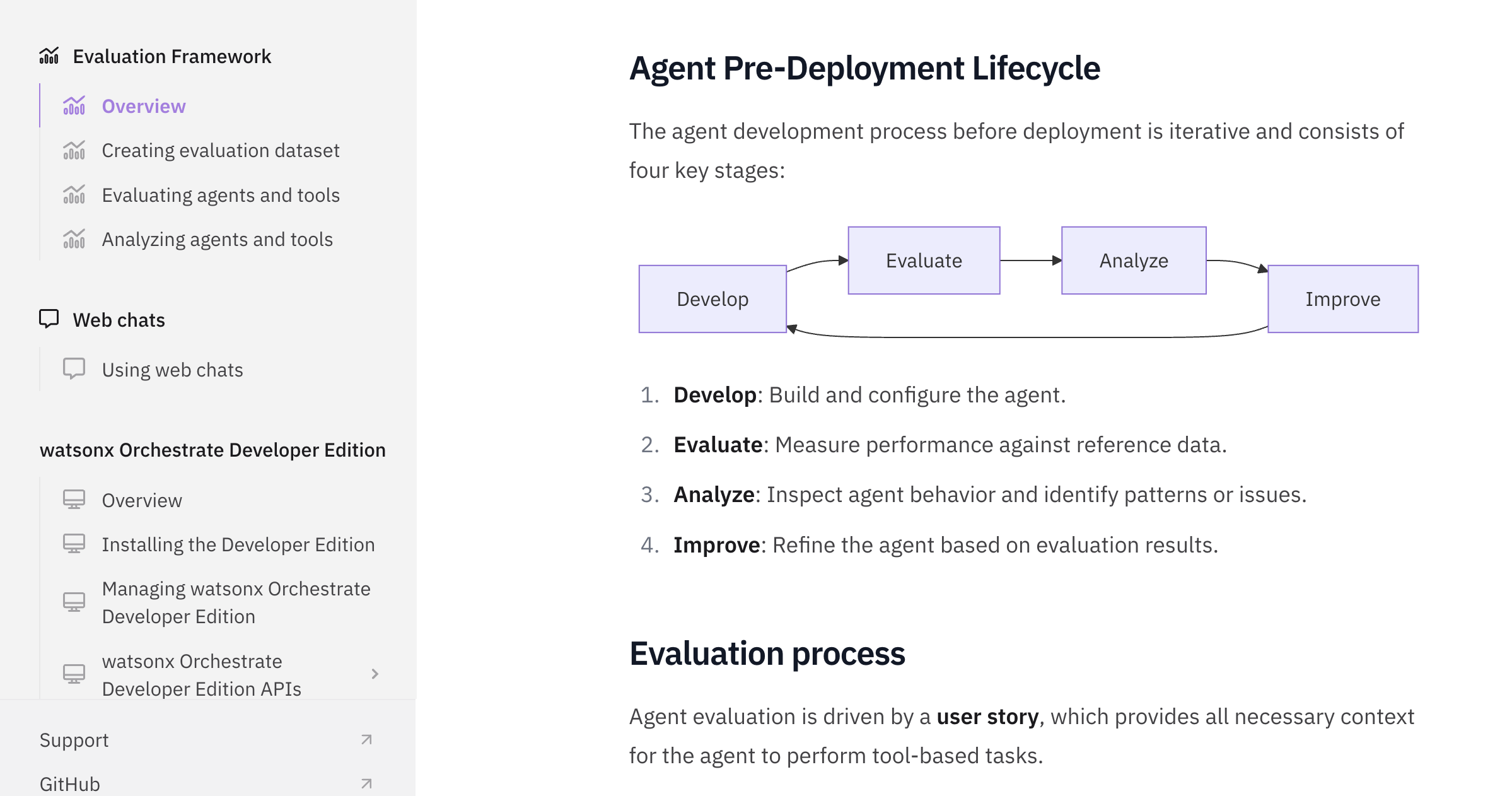
There is a lot of buzz around autonomous agents. However, agents can fail. In these cases, it’s important for developers and AI engineers to understand why they fail to improve prompts, models and tools. This post describes how agents in watsonx Orchestrate can be evaluated.
Watsonx Orchestrate is IBM’s platform to build and run agentic systems. Agents can orchestrate work by delegating tasks to multiple agents and tools. You can start simple by leveraging the Orchestrate user interfaces, but as a developer you can also get full control by writing code.
The watsonx Orchestrate Agent Developer Kit comes with an evaluation framework for developers. As described in my post Why Agents and Agentic Systems can fail it’s important to test not only the final answers, but also the intermediate steps, for example the order of tool calls. The new evaluation framework supports this by defining ground truth information including trajectories.
Example Scenario
Let’s look at an example which is a simple HR agent with three tools.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
{
"spec_version": "v1",
"style": "default",
"name": "hr_agent",
"llm": "watsonx/meta-llama/llama-3-2-90b-vision-instruct",
"description": "A HR Agent that can answer questions related to timeoff and holiday calendar",
"instructions": "Use the tools provided to answer the user's question. If you do not have enough information to answer the question, say so. If you need more information, ask follow up questions.",
"collaborators": [],
"tools": [
"get_assignment_id_hr_agent",
"get_timeoff_schedule_hr_agent",
"get_direct_reports_hr_agent"
]
}
The three tools only return some hardcoded data.
Let’s look at a sample conversation:
- User: I want to know my timeoff schedule for a certain period
- Agent: What is your username?
- User: nwaters
- [Agent invokes tool: get_assignment_id_hr_agent, args: username=nwaters]
- Agent: What is the start date of the timeoff schedule you want to know, in YYYY-MM-DD format?”
- User: 2025-01-01
- Agent: What is the end date of the timeoff schedule you want to know, in YYYY-MM-DD format?
- User: 2025-03-03
- [Agent invokes tool: get_timeoff_schedule_hr_agent, args: start_date=2025-01-01, end_date=2025-03-03, assignment_id=15778303]
- Agent: Your timeoff schedule for the period from 2025-01-01 to 2025-03-03 is on 2025-01-05.
Ground Truth Datasets
Evaluations require ground truth datasets. These datasets contain user stories, user input, sequences of tool invocations and final answers.
Agent evaluation is driven by a user story, which provides all necessary context for the agent to perform tool-based tasks.
A trajectory is a sequence of actions taken by an agent in response to a user query.
For the example above there are two test cases.
- data_simple: ‘I want to know my timeoff schedule for a certain period’
- data_complex: ‘I want to know the timeoff schedule for my reports for a certain period’
Let’s look at the simple case.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
{
"agent": "hr_agent",
"goals": {
"get_assignment_id_hr_agent-1": [
"get_timeoff_schedule_hr_agent-1"
],
"get_timeoff_schedule_hr_agent-1": [
"summarize"
]
},
"goal_details": [
{
"type": "tool_call",
"name": "get_assignment_id_hr_agent-1",
"tool_name": "get_assignment_id_hr_agent",
"args": {
"username": "nwaters"
}
},
{
"type": "tool_call",
"name": "get_timeoff_schedule_hr_agent-1",
"tool_name": "get_timeoff_schedule_hr_agent",
"args": {
"assignment_id": "15778303",
"end_date": "2025-01-30",
"start_date": "2025-01-01"
}
},
{
"name": "summarize",
"type": "text",
"response": "Your time off schedule is on January 5, 2025.",
"keywords": [
"January 5, 2025"
]
}
],
"story": "You want to know your time off schedule. Your username is nwaters. The start date is 2025-01-01. The end date is 2025-01-30.",
"starting_sentence": "I want to know my time off schedule"
}
Under the goals section it can be defined which tools must be invoked before other tools. In the following example ‘get_assignment_id_hr_agent-1’ needs to be run before ‘get_timeoff_schedule_hr_agent-1’.
1
2
3
"get_assignment_id_hr_agent-1": [
"get_timeoff_schedule_hr_agent-1"
]
The Python function expects the assignment id as input parameter.
1
2
3
@tool(name="get_timeoff_schedule_hr_agent", description="get timeoff_schedule", permission=ToolPermission.ADMIN)
def get_timeoff_schedule_hr_agent(assignment_id: str, start_date: str, end_date: str) -> str:
...
The ‘summarize’ goals create the final answers.
Running Evaluations
Once you have ground truth datasets the following command can be invoked to run the evaluations.
1
orchestrate evaluations evaluate -p ./examples/evaluations/evaluate -o ./debug --env-file .env-dev
The intermediate steps of the two test cases are displayed in the terminal.
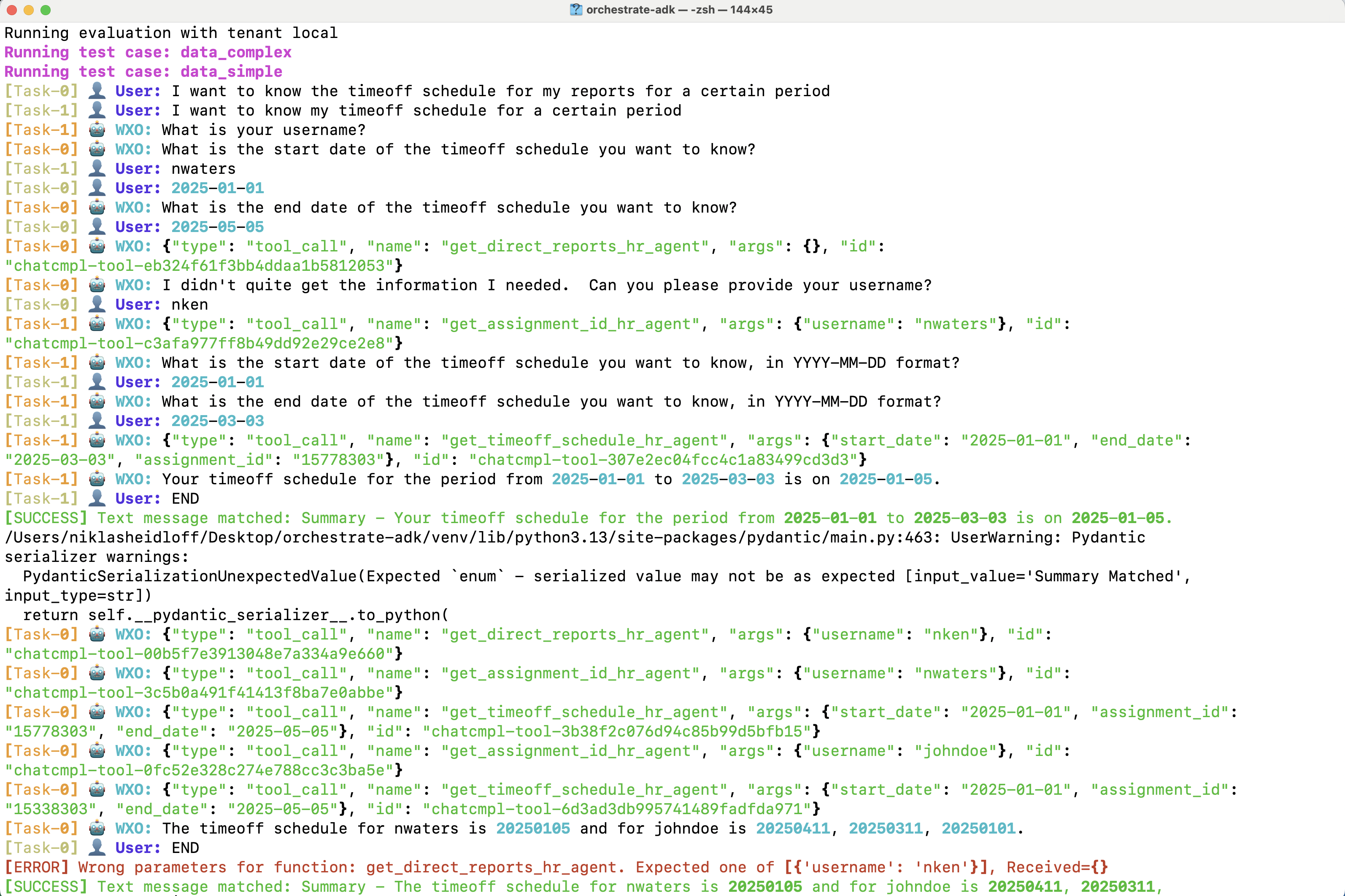
There is also a summary table. Note that RAG use cases (knowledge bases) can also be evaluated.
To provide user input another agent is used that simulates users. This agent has its own prompt and generates user input based on the story from the ground truth dataset, the agent and tool definitions. You can overwrite the configuration in a ‘config.yml’ file.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
auth_config:
tenant_name: local
token: eyJhbxxx...
url: http://localhost:4321
data_annotation_run: false
enable_manual_user_input: false
enable_verbose_logging: true
llm_user_config:
model_id: meta-llama/llama-3-405b-instruct
prompt_config: /Users/niklasheidloff/Desktop/orchestrate-adk/venv/lib/python3.13/site-packages/wxo_agentic_evaluation/prompt/llama_user_prompt.jinja2
user_response_style: []
num_workers: 2
output_dir: ./debug
provider_config:
model_id: meta-llama/llama-3-405b-instruct
provider: watsonx
skip_available_results: false
test_paths:
- ./examples/evaluations/evaluate
wxo_lite_version: 1.8.0
Analyzing Results
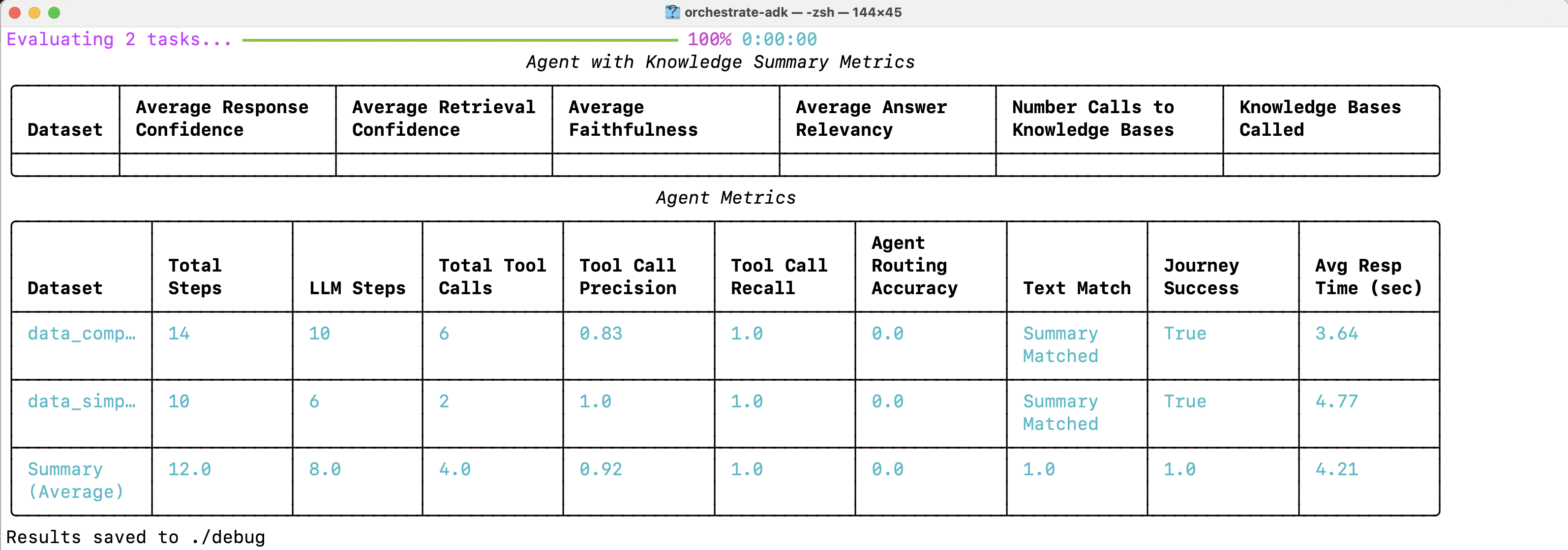
While the simple test case worked, the complex one required an additional unnecessary tool invocation.
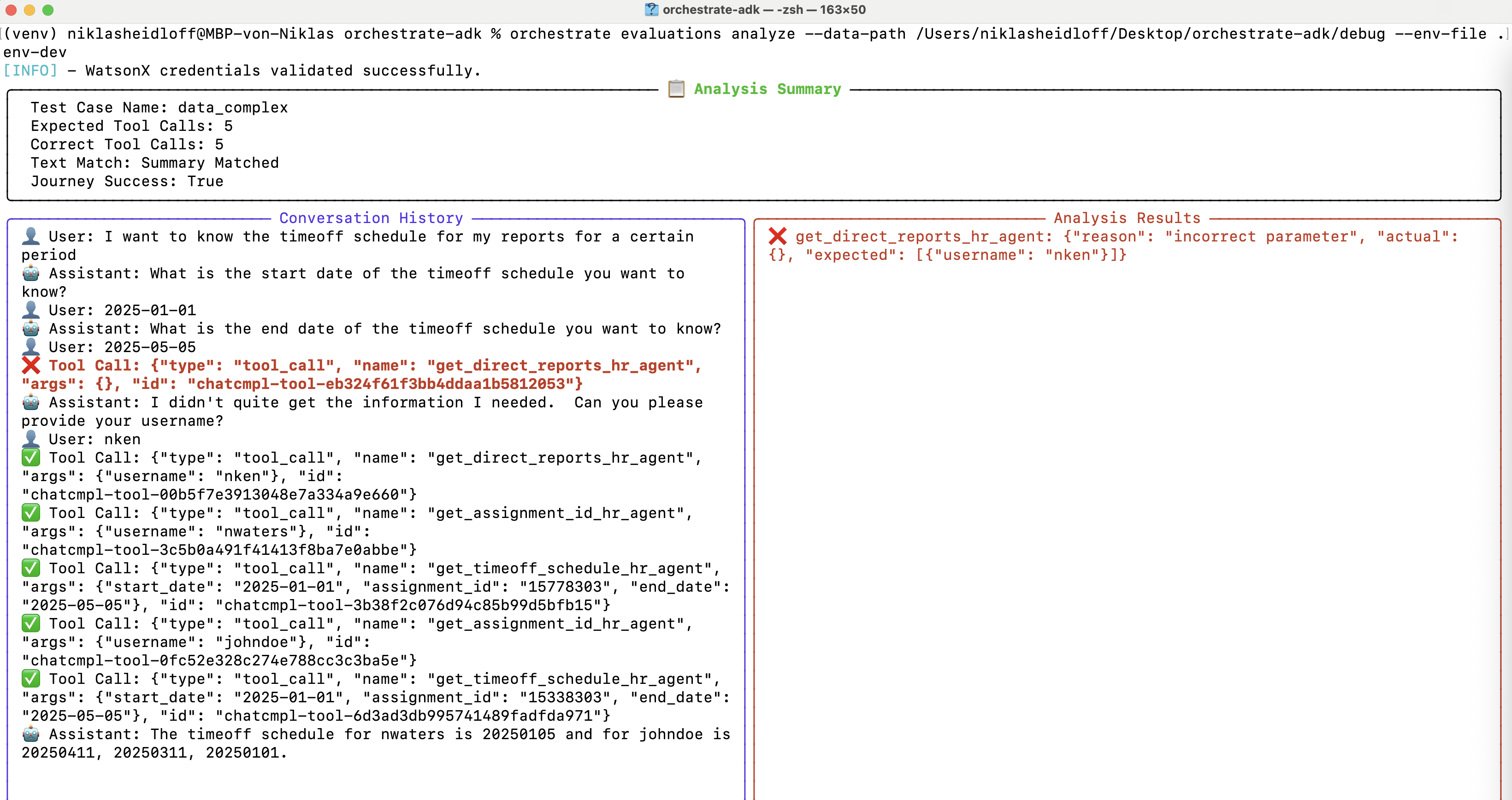
The ‘analyze’ command brings up an easier way to read the results. Additionally, all results are stored in a ‘debug’ directory.
1
orchestrate evaluations analyze --data-path /Users/niklasheidloff/Desktop/orchestrate-adk/debug --env-file .env-dev
The first time the tool ‘get_direct_reports_hr_agent’ was invoked the username was missing. You could try to fix this by changing the prompts and tool descriptions or choosing other models.
Next Steps
To find out more, check out the following resources: