
Recently IBM has added a beta version of the new Apache Spark service to IBM Bluemix. Apache Spark is a fast and general engine for large-scale data processing. Performance benchmarks have shown that it can be up to 100 times faster than Hadoop.
The Spark beta service on Bluemix can only be used as part of the Apache Spark Starter on Bluemix which comes with a SWIFT Object Storage service for the storage of files and integrated Jupyter Notebooks for interactive and reproducible data analysis and visualization. Notebooks are essentially web based IDEs for data scientists to program and document their algorithms.
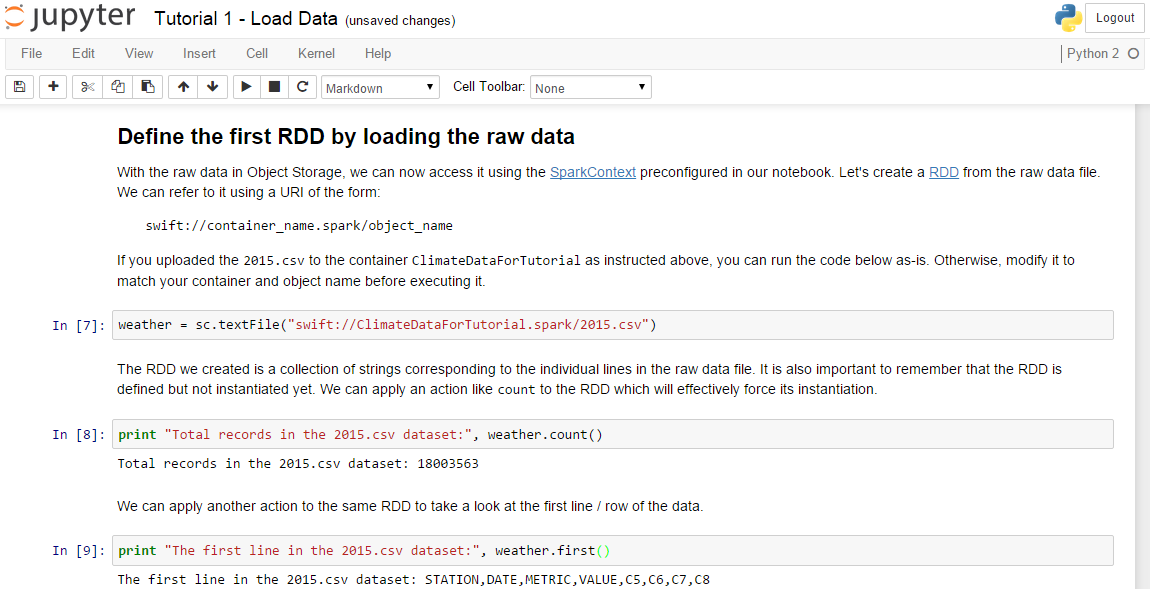
The Spark Starter includes three sample notebooks that show how to use Python and Scala as programming languages. All samples use publically accessible weather data that needs to be uploaded to the object storage service. The screenshot below is from the sample to identify the 10 weather stations with the highest amount of average precipitations in the US. With the first three lines data is loaded and then the amount of entries and the first entry is printed out.
To learn more read the articles from my colleague Luis Arellano Introducing IBM Analytics for Apache Spark and Top 5 Tips to get Started On Apache Spark.