
This post is the first one of a mini series which describes an AI text classification sample end to end. The sample covers the AI lifecycle, from data preparation, over training to deployment on Kubernetes. Watson NLP (Natural Language Understanding) and Watson Studio are used for the training. At runtime Watson NLP is run as container on Kubernetes.
IBM Watson NLP (Natural Language Understanding) containers can be run locally, on-premises or Kubernetes and OpenShift clusters. Via REST and gRCP APIs AI can easily be embedded in applications. IBM Watson Studio is used for the training of the model.
The code is available as open source in the text-classification-watson-nlp repo.
Here are all parts of the series:
- Introduction: Text Classification Sample for IBM Watson NLP
- Step 1: Converting XML Feeds into CSVs with Sentences
- Step 2: Labelling Sentences for Text Classifications
- Step 3: Training Text Classification Models with Watson NLP
- Step 4: Running Predictions against custom Watson NLP Models
- Step 5: Deploying custom Watson NLP Text Classification Models
Scenario
The goal is to classify blog posts from my website heidloff.net whether or not they are related to IBM’s Embeddable AI portfolio. To deliver a better experience than just full text searches for keywords, the model should be smart enough to understand the context. For example, Watson Studio can be used for Watson NLP, but also covers other use cases which are not related to Embeddable AI.
- Related to Watson Embed: IBM Watson NLP, Embeddable AI, Watson Libraries, Watson Containers, etc.
- Potentially related to Watson Embed: IBM Watson Studio, REST, training, etc.
- Typically not related: IBM Watson Assistant, Watson Disovery, TensorFlow, etc.
Solution
The solution contains five steps about which I’ll blog separately. The core idea is to label sentences in my blogs whether or not they fall under the Embedded AI category. With the open source tool Label Sleuth the labelling can be done efficiently and only for the most important sentences. If at least one sentence is classified as related to Embedded AI, the complete blog post is classified as such as well.
Result
The data is split in training and test data. After the training tests are run in the notebook.
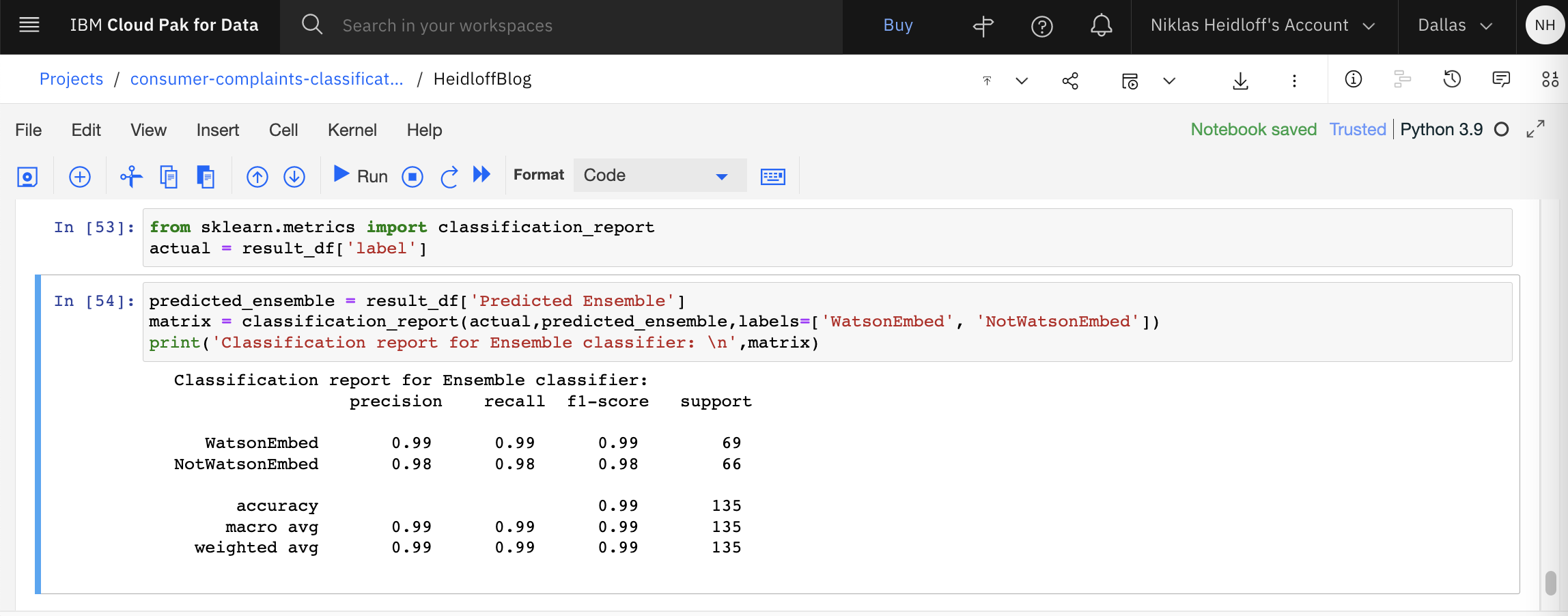
At runtime the predictions are not done via notebooks, but by custom applications. I’ve implemented Node.js code that invokes Watson NLP via REST. Let’s look at two samples.
Sample post that is related to Embeddable AI, but doesn’t mention ‘Embed’ explicitly:
Cool new Capabilities
IBM Watson NLP (Natural Language Understanding) and Watson Speech containers can be run locally, on-premises or Kubernetes and OpenShift clusters. Via REST and gRCP APIs AI can easily be embedded in applications. This post describes how to package custom models in container images for deployments.The custom model predicts that the post is related to ‘WatsonEmbed’ which is correct:
$ node predict.js heidloffblog ../data/heidloffblog/ watson-embed-containers.xml ensemble_model_heidloff
Article IS about WatsonEmbed since the confidence level of one sentence is above 0.8
The sentence with the highest confidence is:
IBM Watson NLP (Natural Language Understanding) and Watson Speech containers can be run locally, on-premises or Kubernetes and OpenShift clusters.
{ className: 'WatsonEmbed', confidence: 0.9859272 }Sample post that is related to Watson Studio, but not in the context of embeddable AI:
1
2
Building Models with AutoML in IBM Watson Studio
Many developers, including myself, want to use AI in their applications. Building machine learning models however, often requires a lot of expertise and time. This article describes a technique called AutoML which can be used by developers to build models without having to be data scientists. While developers only have to provide the data and define the goals, AutoML figures out the best model automatically. There are several ways for developers to use AI without having to be a data scientist ...
The custom model predicts that the post is not related to ‘WatsonEmbed’ which is correct:
1
2
3
4
5
$ node predict.js heidloffblog ../data/heidloffblog/ not-watson-embed-studio.xml ensemble_model_heidloff
Article IS NOT about WatsonEmbed since the confidence level of no sentence is above 0.8
The sentence with the highest confidence is:
For example IBM provides Watson Machine Learning to identify the best algorithm.
{ className: 'WatsonEmbed', confidence: 0.6762146 }
What’s next?
Check out my blog for more posts related to this sample or get the code from GitHub. To learn more about IBM Watson NLP and Embeddable AI, check out these resources.