
This article describes an easy way for developers to deploy PostgreSQL (or Postgres) on Red Hat OpenShift.
Managed Services
There are multiple ways to use Postgres in the cloud. One way is to use IBM’s managed Postgres service Databases for PostgreSQL. The big advantage of managed services is that you don’t have to worry about managing, operating and maintaining the database systems and your data. As soon as you deploy services in your own clusters, you are usually responsible for managing them. Even if you use operators which help with day 2 tasks, you will have to perform some extra work compared to managed services.
Developer Perspective
As a developer I want to write code and be productive as soon as possible. Setting up infrastructure should be as painless as possible. Especially for the early stages in projects I don’t need infrastructure that could be used in production. For example even databases that don’t persist data are often sufficient in these stages.
Managed services are often an option, but sometimes it’s also desirable to set up services like databases in your own clusters, for example if this makes the creation of the schema and sample data easier, if you don’t want to handle secure connectivity and certificates, if you don’t want to set up users, roles and access rights, etc. In these cases I like being able to set up infrastructure myself, if it’s fast, easy and doesn’t cost me anything.
Postgres Image
In order to deploy Postgres to Kubernetes and OpenShift clusters, you obviously need to use containers. For Postgres there are several different images. The challenge is to find the right one. For the requirements of my sample application the ‘postgres’ image is the right one.
You can find the source code of the complete sample Application Modernization – From Java EE in 2010 to Cloud-Native in 2021 on GitHub.
The custom Dockerfile extends the postgres image and sets access rights, especially to make sure that the container runs as non-root.
1
2
3
4
5
6
7
FROM postgres:12
RUN mkdir temp
RUN groupadd non-root-postgres-group
RUN useradd non-root-postgres-user --group non-root-postgres-group
RUN chown -R non-root-postgres-user:non-root-postgres-group /temp
RUN chmod 777 /temp
USER non-root-postgres
Deployment to OpenShift
In order to deploy the image to OpenShift, you need additional yaml configuration. In this file you can define the connection information.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
containers:
- env
- name: POSTGRES_DB
value: postgres
- name: POSTGRES_USER
value: postgres
- name: POSTGRES_PASSWORD
value: postgres
- name: PGDATA
value: /temp/data
image: image-registry.openshift-image-registry.svc:5000/postgres/non-root-postgres:latest
imagePullPolicy: Always
name: postgres
ports:
- containerPort: 5432
protocol: TCP
resources:
limits:
cpu: 60m
memory: 512Mi
requests:
cpu: 30m
memory: 128Mi
restartPolicy: Always
To deploy the container, build the non-root image and push it to a registry (see script) and invoke these commands.
1
2
3
$ oc new-project postgres
$ oc apply -f ./postgres.yaml
$ oc expose svc/postgres
In order to access the database from other containers running in the same cluster use the name ‘postgres:postgres:5432 and the same configuration as above. In order to access the database from external processes use the OpenShift route.
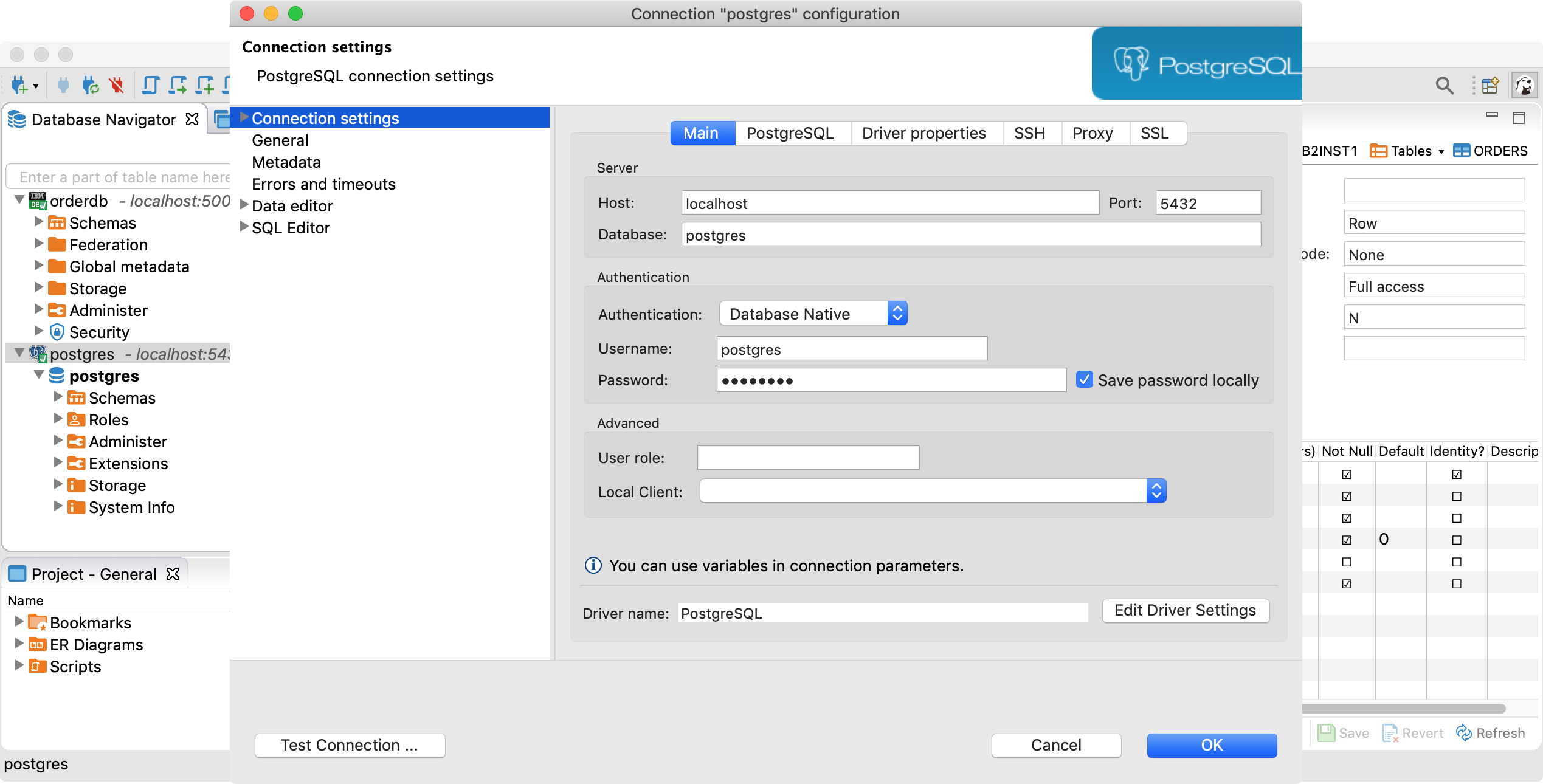
The screenshot shows how to connect to Postgres running in a local container from DBeaver.
Next Steps
As an alternative to the approach above you could also use an OpenShift template to deploy Postgres.
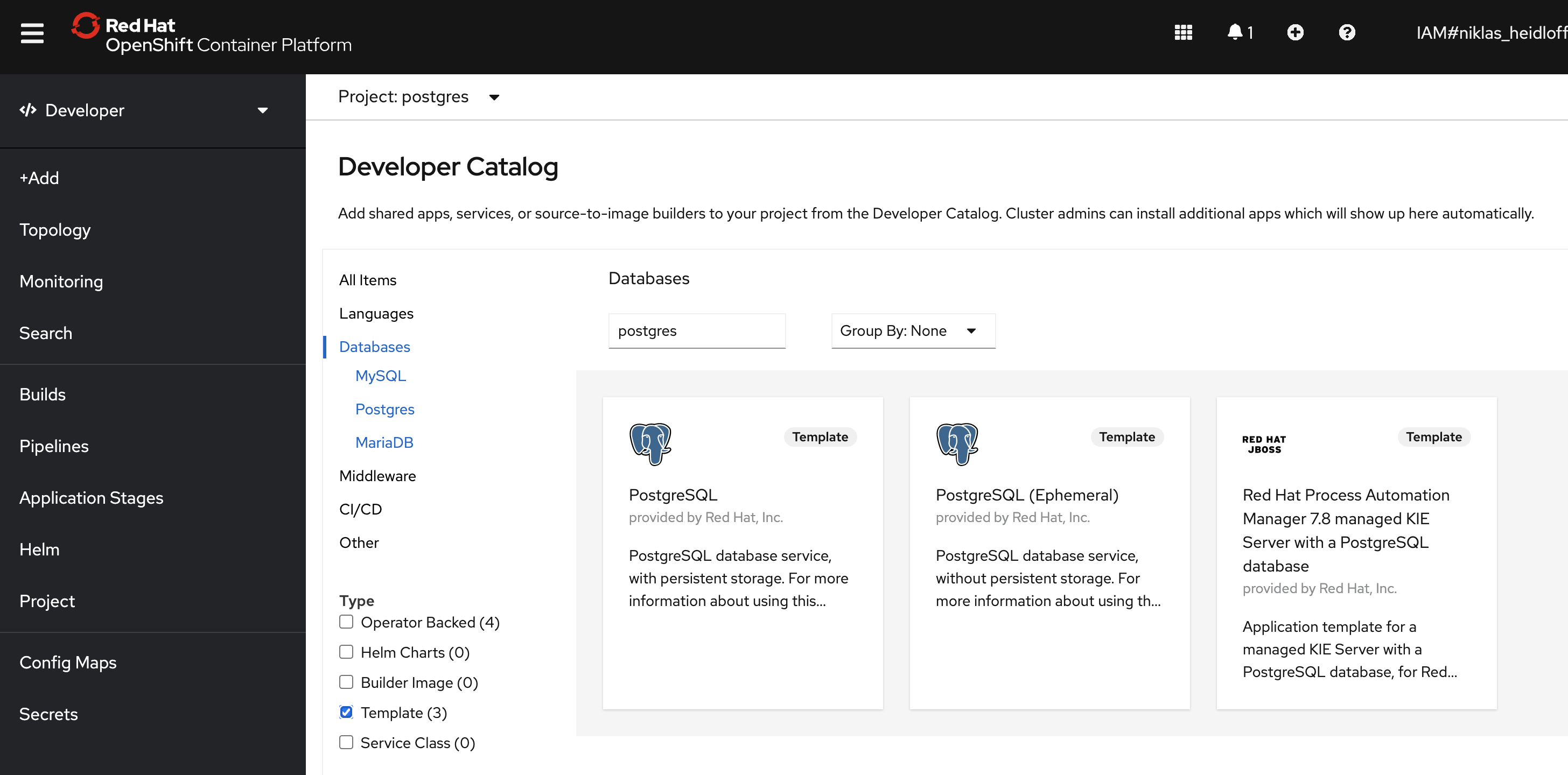
There are also many Postgres operators. To find the right one for your specific requirements is sometimes not trivial. Most of them support HA which makes the setup more difficult than the straight forward approach above.
To learn more about Db2, OpenShift deployments via Tekton and ArgoCD and application modernization, check out the Application Modernization – From Java EE in 2010 to Cloud-Native in 2021 on GitHub.