
Last month IBM announced the general availability of Watson Machine Learning which can be used by data scientists to create models and it can be used by developers to run predictions from their applications. Below is a simple sample walkthrough.
As sample scenario I’ve chosen the Titanic dataset to predict whether people would have survived based on their age, ticket class, sex and number of siblings and spouses aboard the Titanic. I picked this dataset because it seems to be used a lot in tutorials and demos how to do machine learning.
There are different ways for data scientists to create models with Watson Machine Learning. I’ve used the simplest approach. With the Model Builder you can create models with a graphical interface without having to write code or understand machine learning.
First I created a new model.

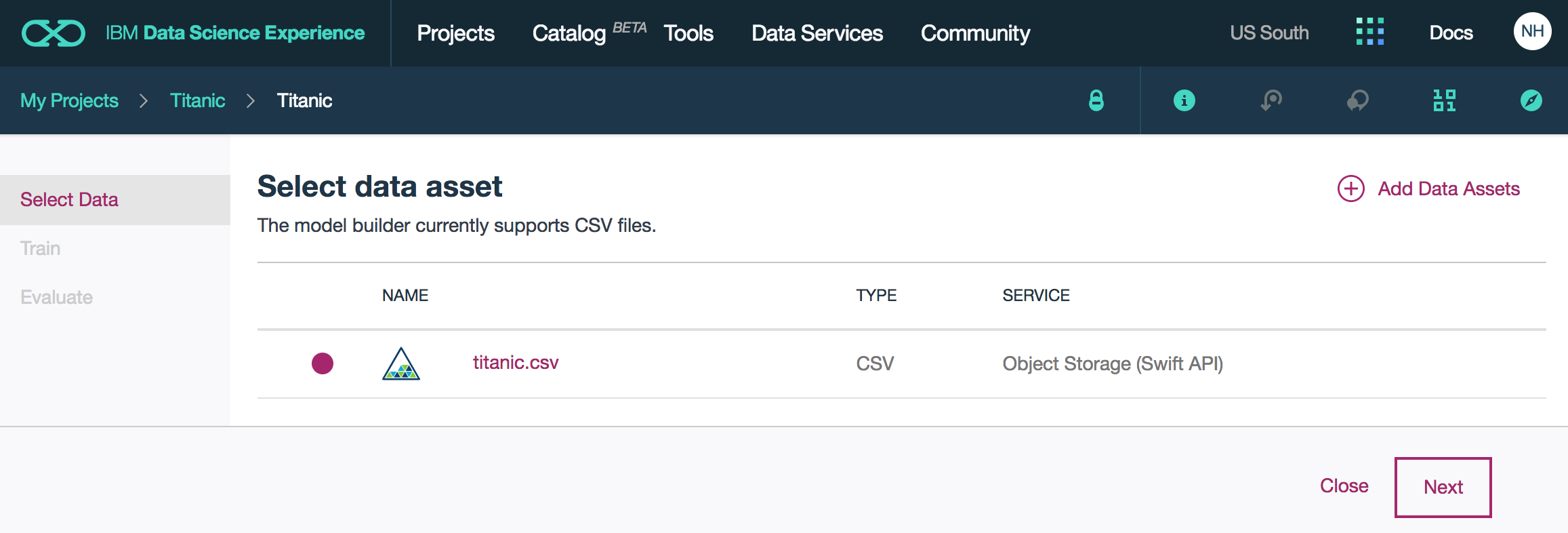
Next I uploaded the Titanic data set (.csv file).
At the top of the next page the label (column to predict) is defined, in this case ‘survived’. Below the label the list of features like age and ticket class are specified. Since in this sample I want to predict ‘survived’ or ‘not survived’ I choose ‘binary classification’. Since I’m not a data scientist I didn’t know which estimators to use and selected all of them.

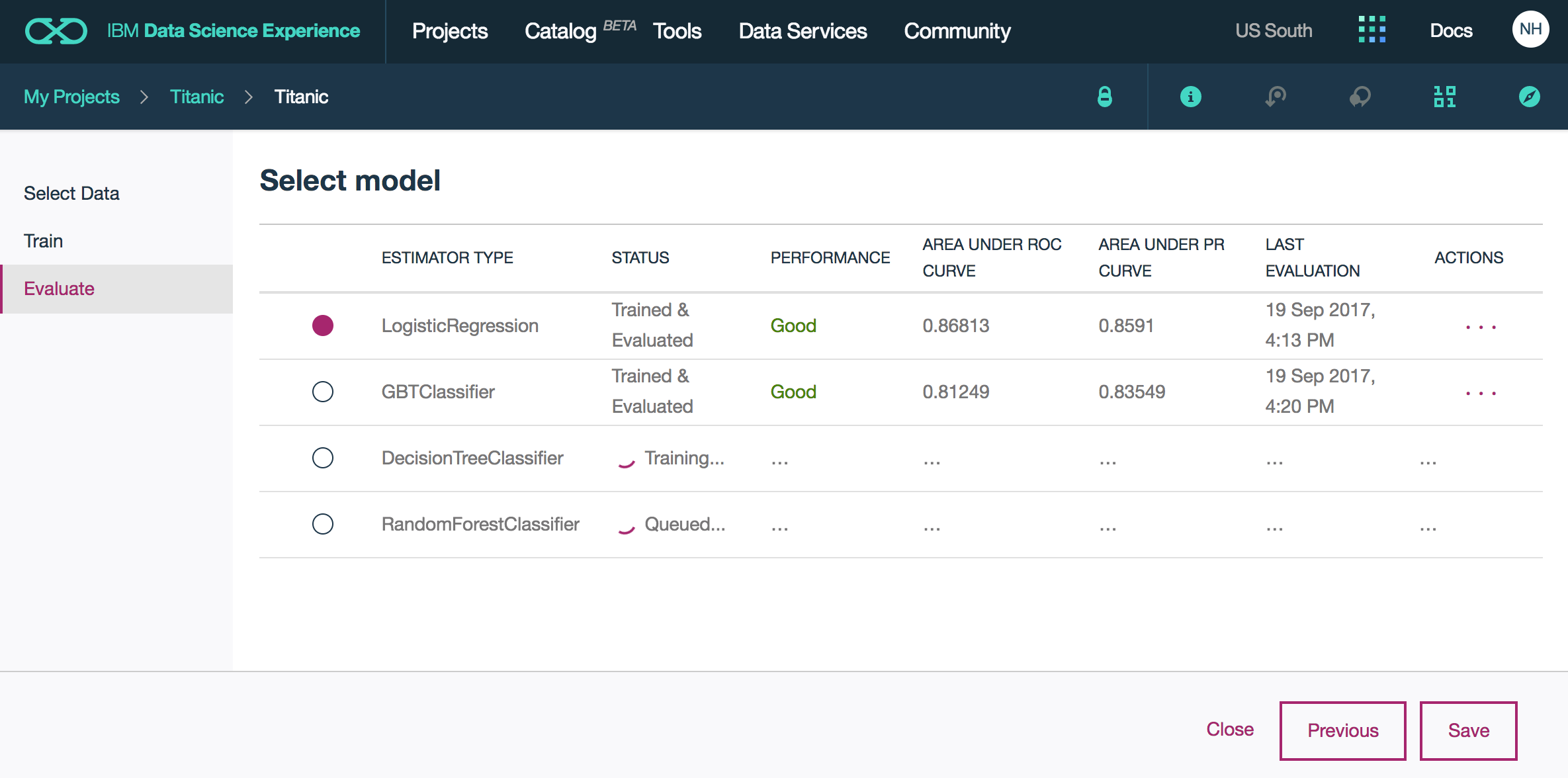
After the training has been completed you can see the results of the different estimators, select the best one and save the model.
In order to run predictions from applications, the model needs to be deployed (bottom of the screenshot).

Once deployed an endpoint is provided to invoke POST requests with input features which returns the prediction. Check out the API explorer for details.

To lean more about Watson Machine Learning open IBM Data Science Experience and give it a try.