
When building applications and microservices for container environments like Kubernetes and OpenShift, efficient usage of resources is key. Similarly to popular frameworks like Node.js/JavaScript, the open source Java framework Quarkus comes with capabilities to build reactive applications to reduce the usage of memory and start up times significantly making Java ready for containers.
This article is part of a series of articles that documents how to modernize a sample Java EE application from 2010 with modern technologies.
The sample application is a simple e-commerce application. The original application and the source code of all subsequent modernization steps is available as open source on GitHub.
Efficiency
In this article I explain how to use Quarkus for the legacy application to leverage the reactive capabilities to save resources (see documentation). As always, when doing these types of tests, note that you mileage will vary.
My earlier article shows that a reactive stack provides response times that take only half of the time compared to the imperative stack. To compare imperative with reactive code, I’ve implemented the same HTTP endpoint twice with Quarkus. The screenshot shows the invocation times after 30000 invocations.
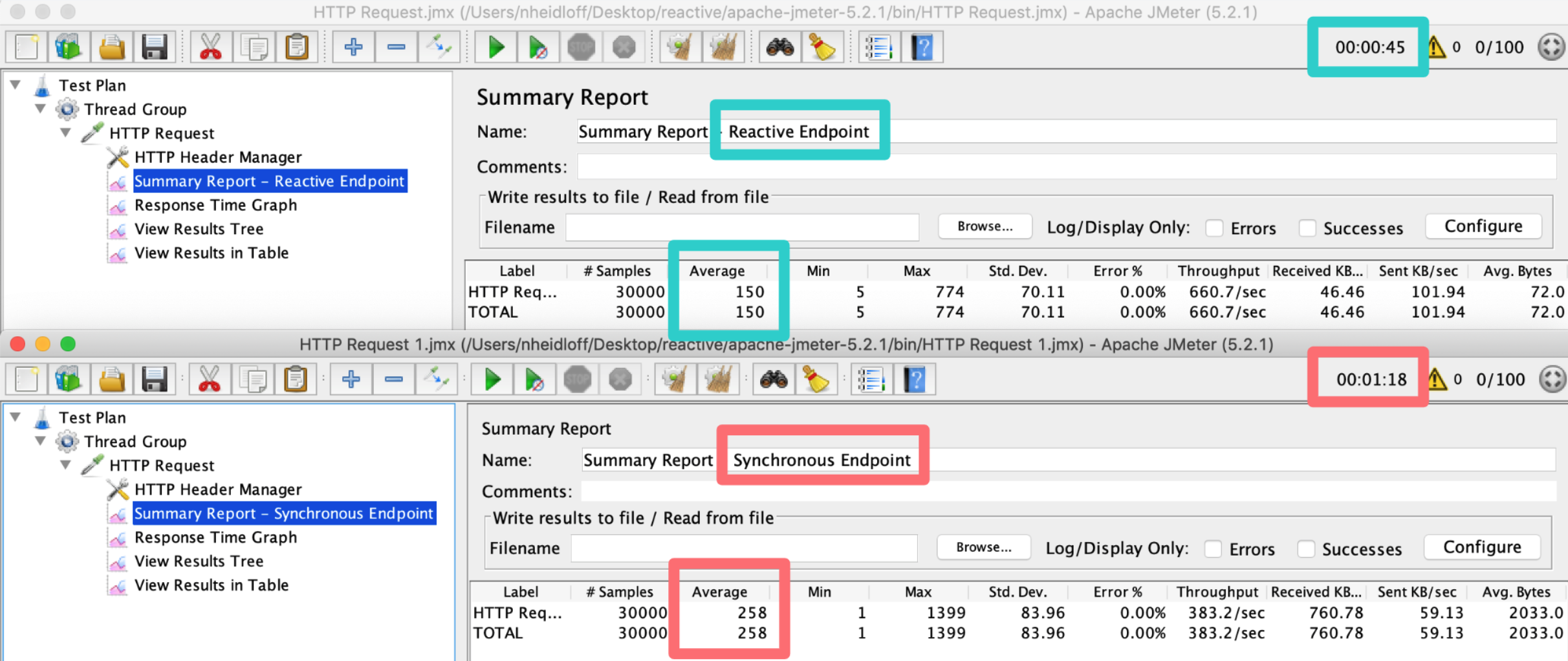
Using Quarkus to run Java EE Applications
In order to use the reactive capabilities in Quarkus, I’ve converted my 10 years old Java EE applications in multiple steps. Check out my previous articles:
As next step I had to actually swap the Java runtime. One of my colleagues wrote an article Learn how to run your standard JAX-RS microservice on Quarkus which describes the key concepts.
I like especially his table that maps Java/Jakarta EE features to Quarkus extensions:

Also note that Quarkus IS NOT a Jakarta EE runtime! So if you want to modernize older Java EE applications which heavily use EE functionality, you are better off using modern frameworks like Open Liberty.
Persistence
The author of the article above points out some necessary changes when changing from Java EE to Quarkus. For example dependency management, context roots and more.
One other key thing to keep in mind is persistence. JPA is a Java standard to access data in relational databases and it’s supported in Jakarta as well as Quarkus. However there are different implementations of JPA like Hibernate and EclipseLink. In Open Liberty, for example, EclipseLink is often much more efficient than Hibernate.
Additionally Quarkus supports a technique called Panache which minimizes the Java persistence code which is also based on Hibernate, but provides new capabilities on top of JPA. There is even work in progress to provide Panache for reactive database access.
Check out the different ways I’ve developed persistence in my sample:
- Quarkus – Reactive (not Panache yet)
- Quarkus – Panache (sync) – Hibernate
- Quarkus – JPA – Hibernate
- Open Liberty – JPA – EclipseLink
Dependencies
Another thing to keep in mind when changing Java EE applications to Quarkus is dependency management.
Quarkus does as much of the heavy lifting as possible at build-time to optimize the run-time experience. That’s why a lot of popular Java libraries have been optimized for Quarkus and can easily be used via Quarkus extensions.
At the same time that means that not every Java library can (efficiently) be used in Quarkus. Here is what the Quarkus architect Emmanuel Bernard wrote on StackOverflow:
As long as your dependency is brought via an extension, then it’s usage via the extension is known to work in native mode. If you directly pull a dependency outside an extension dependency, then Quarkus can’t guarantee this.
If there is no Quarkus extension, you can always build your own one.
In my example there was no extension for com.ibm.websphere.appserver.api.json. However most of the WebSphere named packages are available in the meantime in standard libraries which didn’t exist when IBM created it’s own libraries. I could easily change from com.ibm.json.java.JSONObject to com.fasterxml.jackson.databind.node.ObjectNode.
- com.ibm.json.java.JSONObject (pom.xml, code)
- com.fasterxml.jackson.databind.node.ObjectNode (pom.xml, code)
What’s next?
To learn more about application modernization, check out my blog series in the GitHub repo.