
Serverless platforms like Apache OpenWhisk are gaining more and more traction. Rather than building only single functions, developers are starting to develop cloud-native applications with many serverless functions/microservices.
The challenge when building serverless applications is how to manage the data flows between the functions, especially if you want loosely coupled functions without dependencies between each other.
In my previous article Data Flows in Serverless Cloud-Native Applications I explained a pattern how to manage the data flows between functions. In this article I will go one step further and describe how functions can define their input and output schemas and how transformations of JSON data can be done.
The complete code of this sample is on GitHub.
I picked a simple scenario application which sends a mail. The serverless application is invoked with two input parameters: person id and subject. For the specific person the full profile is received which contains the email address. The last function sends a mail to this email address with the defined subject.
There are only two ‘real’ functions that are executed sequentially: 1. read person profile, 2. send mail. Before they are executed however, additional ‘transformation’ functions are invoked which transform the data into the exact format that is expected. Here is the code of the application:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
composer.try(
composer.sequence(
composer.task('composer-demo-nh/transform-read-person-profile', { merge: true }),
composer.task('composer-demo-nh/read-person-profile', { merge: true }),
composer.task('composer-demo-nh/transform-send-mail', { merge: true }),
composer.task('composer-demo-nh/send-mail', { merge: true })
),
params => {
return {
ok: false,
'message': 'An error has occured in the app send-mail-app',
'error-from-function': params.error
}
}
)
Let’s take a look at the function that reads the user profile. The function expects a person id and returns a person profile including an email address. The inputs and outputs are defined via JSON Schema.
Check out the schema of the person profile which is the output. The input schema is simple since it only contains one id:
1
2
3
4
5
6
7
8
9
10
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"properties": {
"id": {
"type": "string"
}
},
"title": "Schema Input of read-person-profile"
}
Since the ‘send mail’ function doesn’t expect the full person profile, but only an email address and a subject (see schema), the data needs to be converted.
For this purpose I use JSONata which is a lightweight query and transformation language for JSON data inspired by semantics of XPath. For Node.js developers there is an npm module which is a JavaScript implementation of JSONata.
This is the ‘transform function‘ which creates the expected input for the ‘send mail’ function. tbd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
const jsonata = require('jsonata');
let main = params => {
try {
let inputApplication = params['input-application'];
let subject = inputApplication.subject;
let outputReadPersonProfile = params['output-read-person-profile'];
let expression = jsonata("Email[type='office'].address[0]");
let email = expression.evaluate(outputReadPersonProfile);
let outputParameters = {
'input': {
'email': email,
'subject': subject
}
}
return outputParameters;
}
catch (error) {
return {
error: 'Error in transform-send-mail'
}
}
}
With jsonata(“Email[type=’office’].address[0]”) the first business email address is returned from the profile.
To summarize I think functions should define their input and output schemas so that, for example, they can be built by different developers and assembled easily in serverless applications. Functions with schemas can also easier be re-used in different applications. The transformations of the data that flows in serverless applications can be done in separate ‘transformation’ functions.
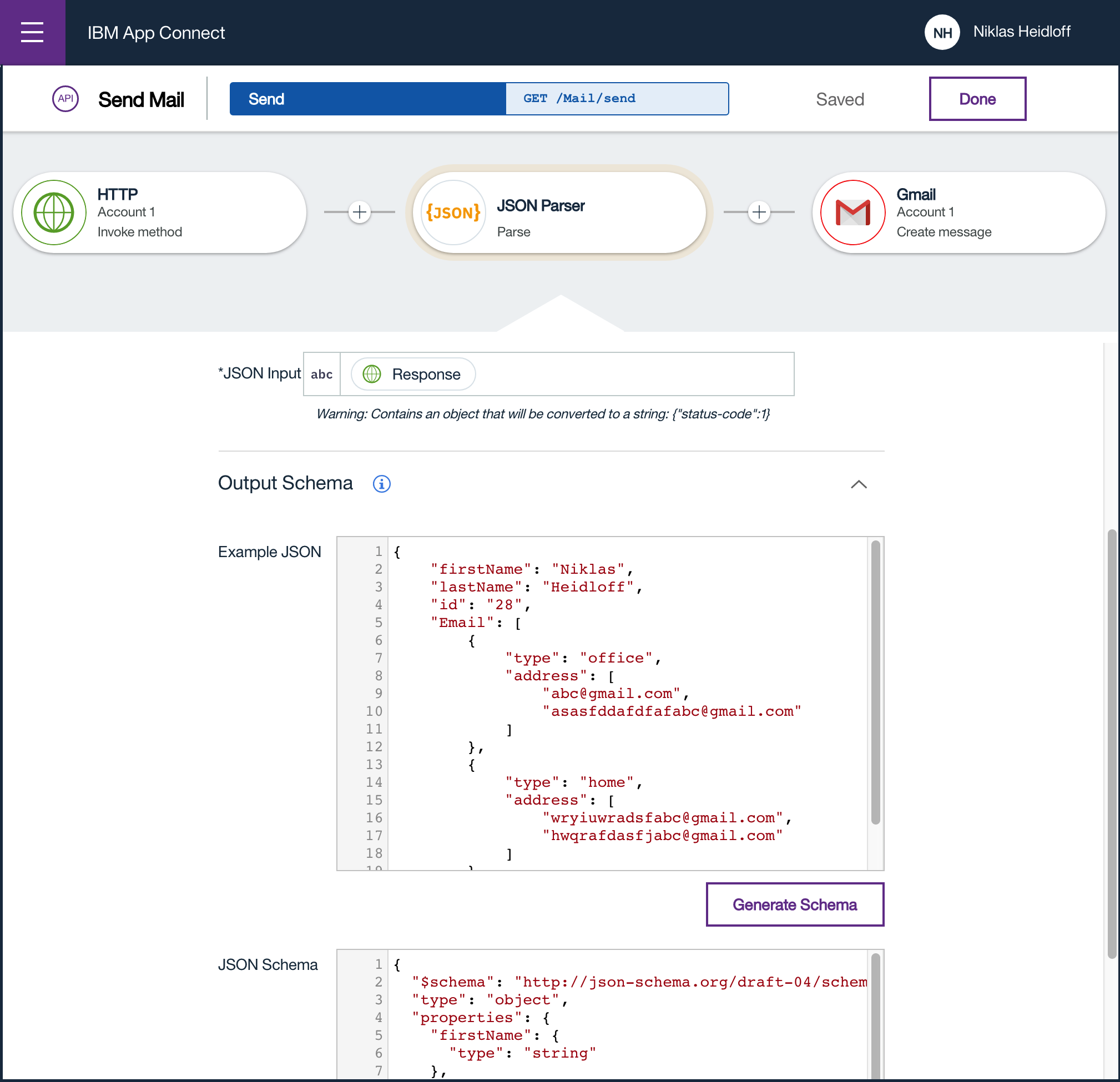
A similar concept is used by IBM App Connect which can be used to integrate different applications without having to code anything. App Connect provides a JSON Parser node where you can enter a schema or sample JSON. Subsequent nodes can then access data from previous nodes declaratively. See my previous article Integrating Applications without writing Code for an example.
I really like the App Connect user experience to select data in JSON. Recently App Connect won the iF Design Award 2018. I think it would be great to see that user experience added to OpenWhisk Composer. Here is a screenshot how the scenario from above could be done via App Connect.
If you want to try out OpenWhisk in the cloud, you can get an account on the IBM Cloud.