
Early this year IBM announced Deep Learning as a Service within Watson Studio. The core of this service is available as open source and can be run on Kubernetes clusters. This allows developers and data scientists to train models with confidential data on-premises, for example on the Kubernetes-based IBM Cloud Private.
The open source version of IBM’s Deep Learning service is called Fabric for Deep Learning. Fabric for Deep Learning supports framework independent training of Deep Learning models on distributed hardware. For the training CPUs can be used as well as GPUs. Check out the documentation for a list of DL frameworks, versions and processing units.

I had open sourced samples that show how to train visual recognition models with Watson Studio that can be deployed to edge devices via TensorFlow Lite and TensorFlow.js. I extended one of these samples slightly to show how to train the model with Fabric for Deep Learning instead. To do this, I only had to change a manifest file slightly since the format expected by Watson Studio is different.
This is the manifest file that describes how to invoke and run the training. For more details how to run trainings on Kubernetes, check out the readme of my project and the Fabric for Deep Learning documentation.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
name: retrain
description: retrain
version: "1.0"
gpus: 2
cpus: 8
memory: 4Gb
learners: 1
data_stores:
- id: sl-internal-os
type: mount_cos
training_data:
container: nh-input
training_results:
container: nh-output
connection:
auth_url: http://169.62.129.231:32551
user_name: test
password: test
framework:
name: tensorflow
version: "1.5.0-gpu-py3"
command: python3 retrain.py --bottleneck_dir ${RESULT_DIR}/bottlenecks --image_dir ${DATA_DIR}/images --how_many_training_steps=1000 --architecture mobilenet_0.25_224 --output_labels ${RESULT_DIR}/labels.txt --output_graph ${RESULT_DIR}/graph.pb --model_dir ${DATA_DIR} --learning_rate 0.01 --summaries_dir ${RESULT_DIR}/retrain_logs
evaluation_metrics:
type: tensorboard
in: "$JOB_STATE_DIR/logs/tb"
To initiate the training, this manifest file and the training Python code needs to be uploaded. In order to do this, you can either use the web user experience or a CLI.
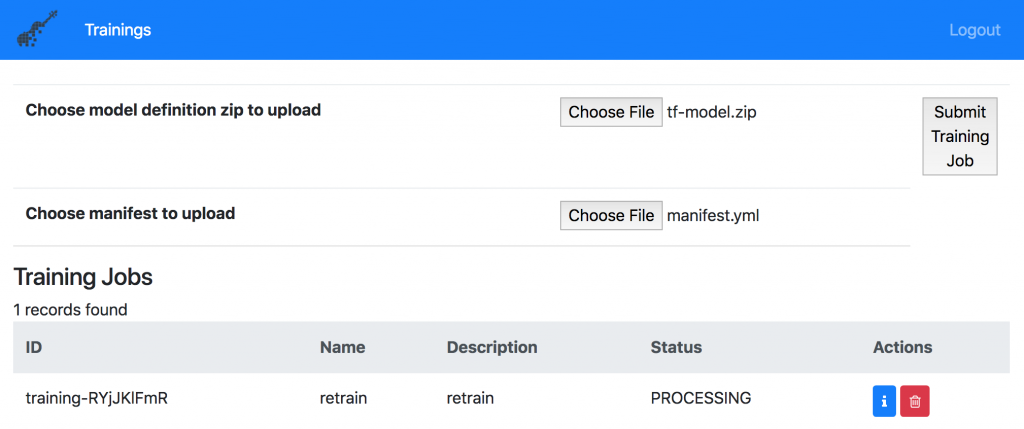
In my example I’ve stored the data on my Kubernetes cluster. Fabric for Deep Learning comes with S3 based Object Storage which means that you can use the AWS CLI to upload and download data. Alternatively you could also use Object Storage in the cloud, for example IBM’s Cloud Object Storage.
To find out more about Fabric for Deep Learning, check out these resources.