
Operators provide huge value by automating day 2 operations for software running on Kubernetes. However, for operator developers there is a steep learning curve. This article describes the key objects and concepts you need to understand before building operators.
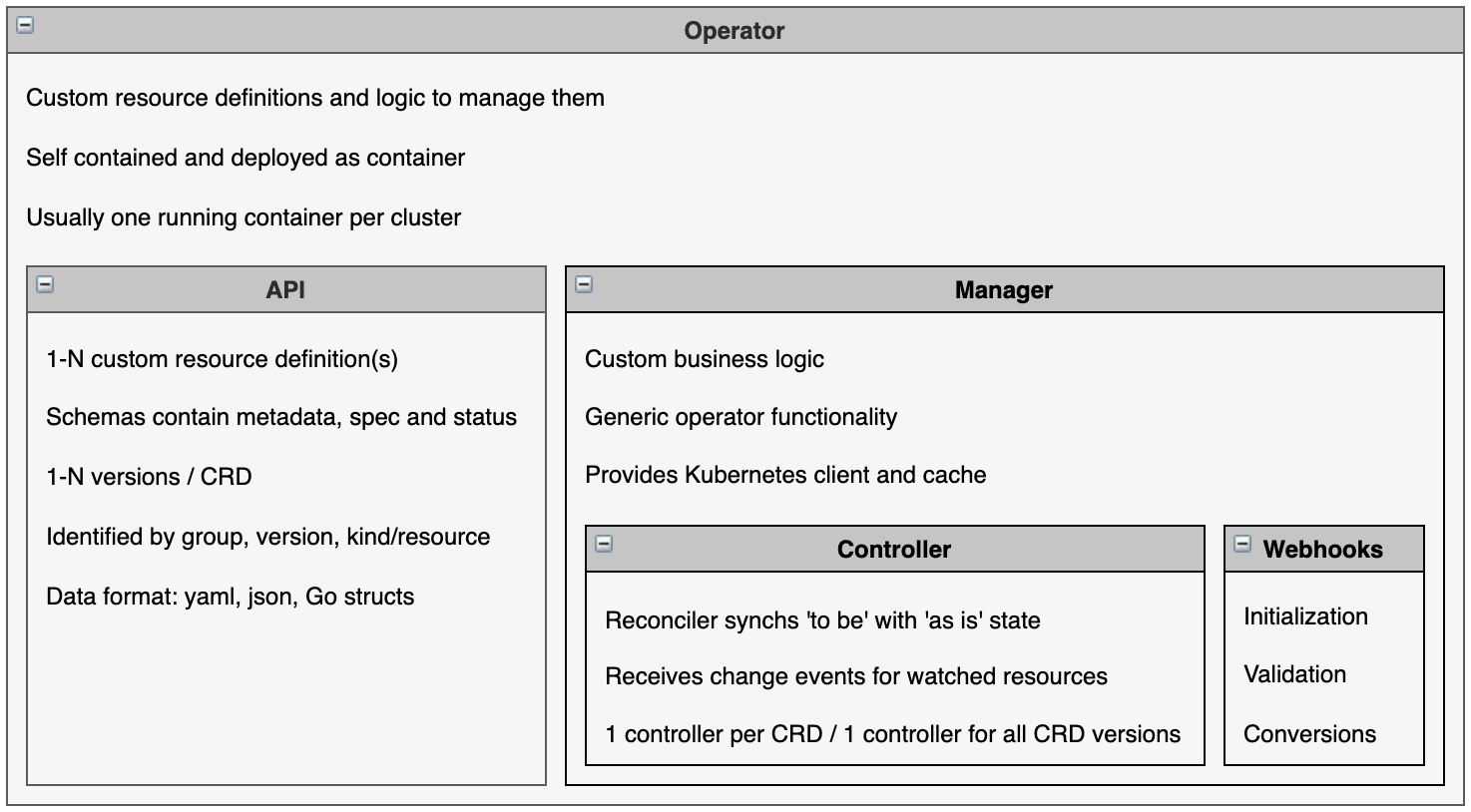
There are several sites, tutorials and articles that describe operators. When I started to work on operators, it would have helped me to understand the metamodel, key concepts and high level architecture first. Unfortunately I didn’t find such an overview. The best overview I found is the Kubebuilder Architecture Concept Diagram. I’ve extended and changed this diagram to add key components that were missing and to help me explaining our clients how operators work. I’ve also simplified the diagram to focus on key capabilities only.
Most of the concepts in the diagram are generic for all types of operators, no matter how they have been implemented. Some parts are specific to operators built with Golang, Operator SDK including Kubebuilder and the Operator Lifecycle Manager Framework.
Below are some more details about the different objects. I have also added links to samples. The samples are part of a bigger sample, called operator-sample-go, which is available on GitHub that describes various operator patterns and best practises.
Operator
The term ‘Operator’ or ‘Kubernetes Operator’ describes the mechanism to automate deployments and day 2 operations for software running on Kubernetes which implements the operator pattern. This pattern is used by Kubernetes internally as well as externally for custom resources. Operators contain custom resource definitions and business logic to manage these resources. The self contained operators are deployed as containers on Kubernetes. Usually there is one running operator instance per cluster. For production deployments the Operator Lifecycle Manager (OLM) provides functionality to deploy and operate the operators, for example to handle multiple versions. Operators are packaged in CSVs (cluster service versions).
Samples:
API
The term API is often used as synonym to custom resource definition. Custom resource definitions have schemas and potentially multiple versions. This allows managing resources declaratively in Kubernetes production environments. Custom resource definitions are identified by their group, version and resource name. One operator can contain multiple resource definitions.
Samples:
Manager
The manager contains the business logic of the operator which knows how to deploy and manage custom resources. Additionally it comes with generic built in functionality to handle HA leader election, export metrics, handle webhook certs and broadcasts events. It also provides a client to access Kubernetes and a cache to improve efficiency.
Sample:
Controller
The main responsibility of controllers is to synchronize the ‘to be’ states as defined in custom resources with the ‘as is’ states in Kubernetes clusters. This includes creations of new resources, updates to existing resources or deletions. This logic is implemented in the controllers’ reconcile function. The reconciler doesn’t use an imperative model to manage resources because of the nature of distributed Kubernetes systems and because of the long time it can take to change resources without blocking anything. Instead the reconciler is invoked over and over again until it signals that it’s done. This is why reconcilers need to be idempotent. One controller manages one custom resource definition including all versions of it. The controller uses caches and Kubernetes clients and gets events via filters.
Samples:
- Flow in Reconcile function
- Synchronization of resources
- Creations and updates of resources
- Definition of resources to watch
Webhooks
With webhooks values of resources can be changed and conversions between different versions can be done.
Samples:
To learn more about operator patterns and best practices, check out the repo operator-sample-go.