
IBM Watson NLP (Natural Language Understanding) and Watson Speech containers can be run locally, on-premises or Kubernetes and OpenShift clusters. Via REST and gRCP APIs AI can easily be embedded in applications. This post describes how to deploy and run Watson NLP and Watson NLP models on Kubernetes via the highly scalable model inference platform KServe ModelMesh.
To set some context, check out the landing page IBM Watson NLP Library for Embed. The Watson NLP containers can be run on different container platforms, they provide REST and gRCP interfaces, they can be extended with custom models and they can easily be embedded in solutions. While this offering is new, the underlaying functionality has been used and optimized for a long time in IBM offerings like the IBM Watson Assistant and NLU (Natural Language Understanding) SaaS services and IBM Cloud Pak for Data.
What is KServe ModelMesh?
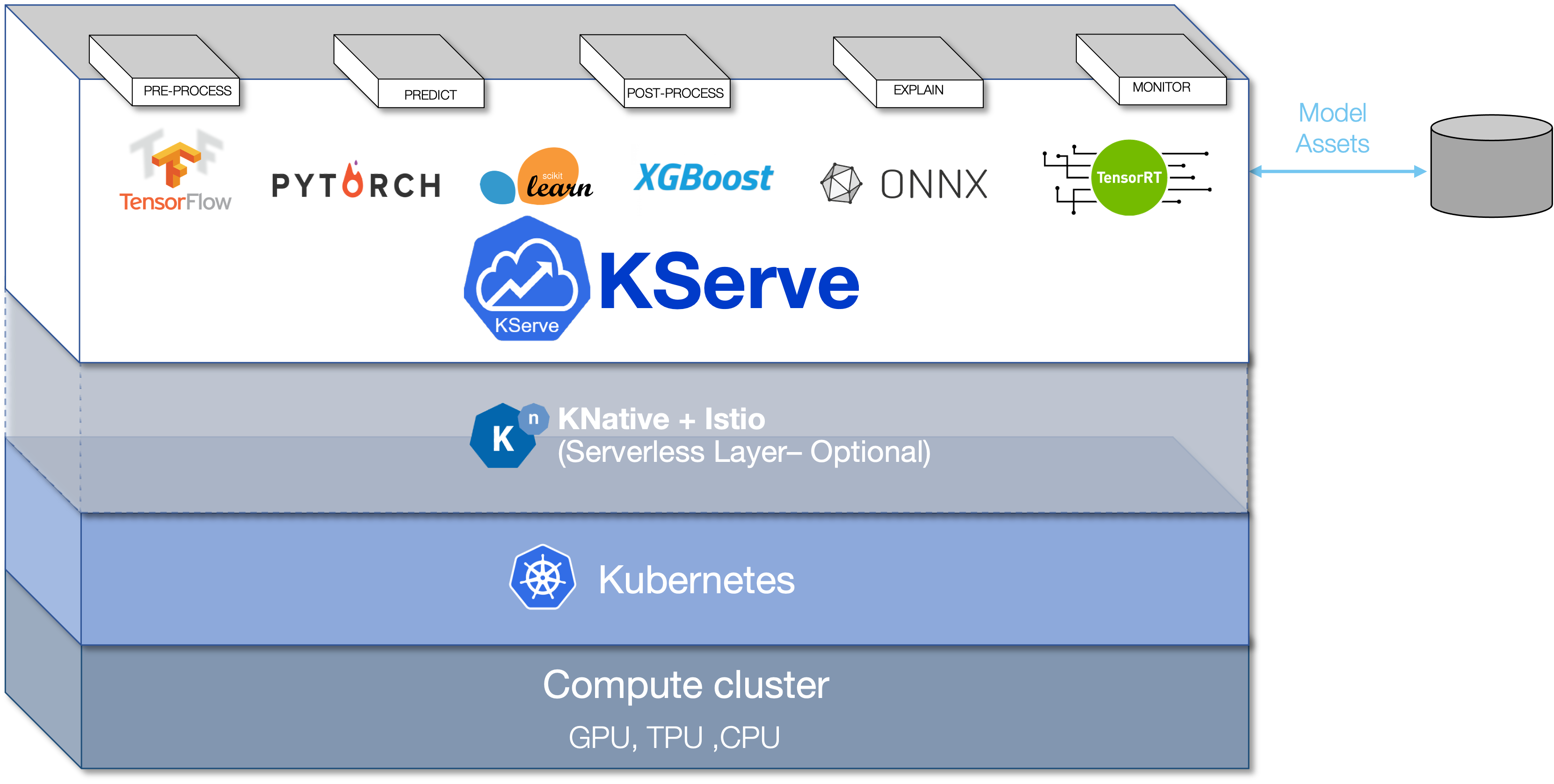
KServe is a Kubernetes-based platform for ML model inference (predictions). It supports several standard ML model formats, including TensorFlow, PyTorch, ONNX, scikit-learn and more. Additionally it is highly scalable and dynamic. KServe ModelMesh is used for sophisticated AI scenarios where multiple models are used at the same time. For example you might have a scenario where you need various NLP models (classification, emotions, concepts, etc.), various Speech models (different qualities, voices, etc.) and all this for for different languages. In this case utting all models in one container is not an option.
Let’s look at the definition from the KServe landing page.
ModelMesh is designed for high-scale, high-density and frequently-changing model use cases. ModelMesh intelligently loads and unloads AI models to and from memory to strike an intelligent trade-off between responsiveness to users and computational footprint.
Why KServe?
- KServe is a standard Model Inference Platform on Kubernetes, built for highly scalable use cases.
- Provides performant, standardized inference protocol across ML frameworks.
- Support modern serverless inference workload with Autoscaling including Scale to Zero on GPU.
- Provides high scalability, density packing and intelligent routing using ModelMesh
- Simple and Pluggable production serving for production ML serving including prediction, pre/post processing, monitoring and explainability.
- Advanced deployments with canary rollout, experiments, ensembles and transformers.
KServe runs on Kubernetes. It requires etcd, S3 storage and optionally Knative and Istio.
The video Exploring ML Model Serving with KServe provides a good introduction and overview.
Deploying Watson NLP Models to KServe ModelMesh
There is a tutorial that provides detailed instructions how to deploy NLP models to KServe. For IBM partners there is also a test environment available. Below are the key steps of the tutorial.
First you need to store predefined or custom Watson NLP models on some S3 complianted cloud object storage. The test environment uses Minio which can be installed in your own clusters. Via the Minio CLI models can be uploaded to buckets. If you use IBM’s Cloud Object Storage, make sure to use the HMAC credentials.
Next you define an instance of the custom resource definition InferenceService per model. In this definition you refer to your model in S3.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
kubectl create -f - <<EOF
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: $NAME
annotations:
serving.kserve.io/deploymentMode: ModelMesh
spec:
predictor:
model:
modelFormat:
name: watson-nlp
storage:
path: $PATH_TO_MODEL
key: $BUCKET
parameters:
bucket: $BUCKET
EOF
To get the endpoints, invoke this command.
1
2
3
4
$ kubectl get inferenceservice
ensemble-classification-wf-en-emotion-stock-predictor grpc://modelmesh-serving.ibmid-6620037hpc-669mq7e2:8033
sentiment-document-cnn-workflow-en-stock-predictor grpc://modelmesh-serving.ibmid-6620037hpc-669mq7e2:8033
syntax-izumo-en-stock-predictor grpc://modelmesh-serving.ibmid-6620037hpc-669mq7e2:8033
To invoke Watson NLP from local code or via commands, forward the port.
1
kubectl port-forward service/modelmesh-serving 8085:8033
Next you need to get the proto files. You can download them from a repo and copy them from the runtime image.
1
2
3
4
$ git clone https://github.com/IBM/ibm-watson-embed-clients
$ cd watson_nlp/protos
or
$ kubectl exec deployment/modelmesh-serving-watson-nlp-runtime -c watson-nlp-runtime -- jar cM -C /app/protos . | jar x
The watson-automation repo shows a little example how to invoke Watson NLP functionality via gRPC.
Installing KServe ModelMesh Serving
See the KServe ModelMesh Serving installation instructions for detailed instructions on how to install KServe with ModelMesh onto your cluster. You need to install etcd, S3, KServe and optionally Istio. Unfortunately there is no operator yet, but a script is provided.
To deploy Watson NLP on KServe, a ServingRuntime instance needs to be defined and applied. A serving runtime is a template for a pod that can serve one or more particular model formats. Apply the following sample to create a simple serving runtime for Watson NLP models:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
apiVersion: serving.kserve.io/v1alpha1
kind: ServingRuntime
metadata:
name: watson-nlp-runtime
spec:
containers:
- env:
- name: ACCEPT_LICENSE
value: "true"
- name: LOG_LEVEL
value: info
- name: CAPACITY
value: "1000000000"
- name: DEFAULT_MODEL_SIZE
value: "500000000"
image: cp.icr.io/cp/ai/watson-nlp-runtime:1.0.20
imagePullPolicy: IfNotPresent
name: watson-nlp-runtime
resources:
limits:
cpu: 2
memory: 16Gi
requests:
cpu: 1
memory: 16Gi
grpcDataEndpoint: port:8085
grpcEndpoint: port:8085
multiModel: true
storageHelper:
disabled: false
supportedModelFormats:
- autoSelect: true
name: watson-nlp
To find out more about Watson NLP and Watson for Embed in general, check out these resources: