
In March IBM announced Deep Learning as a Service (DLaaS) which is part of IBM Watson Studio. Below I describe how to use this service to train models and how to optimize hyperparameters to easily find the best quality model.
I’m not a data scientist, but have been told that finding the right hyperparameters is often a tedious task with a lot of trial and error. Here is the intro of the service from the documentation:
As a data scientist, you need to train numerous models to identify the right combination of data in conjunction with hyperparameters to optimize the performance of your neural networks. You want to perform more experiments faster. You want to train deeper networks and explore broader hyperparameters spaces. IBM Watson Machine Learning accelerates this iterative cycle by simplifying the process to train models in parallel with an on-demand GPU compute cluster.
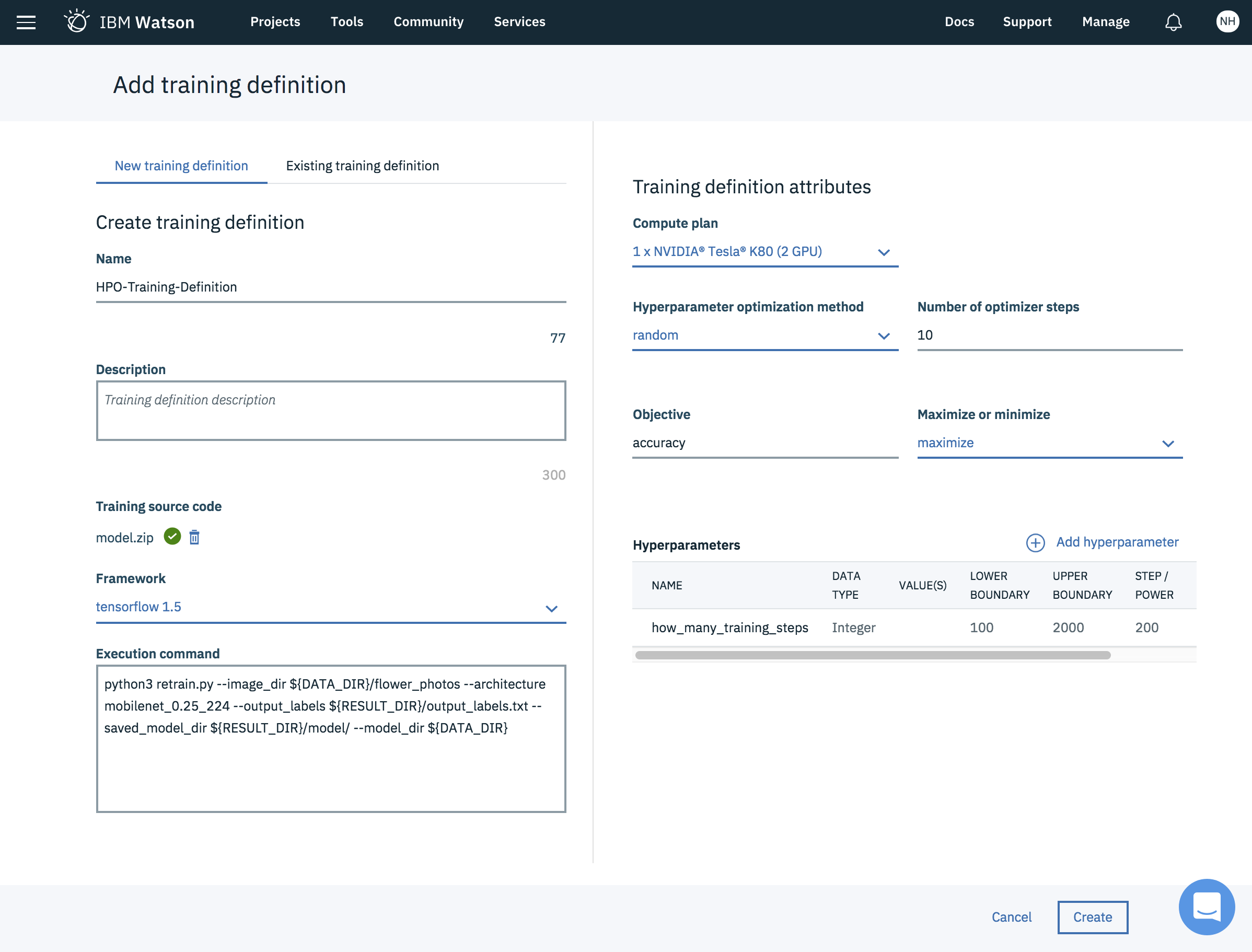
To learn the ability to optimize hyperparameters (HPO), I’ve used TensorFlow For Poets to classify images of flowers via transfer learning. Via HPO the number of training steps is optimized.
This is a screenshot of IBM Watson Studio with a training definition and one hyperparamter ‘how_many_training_steps’ with values between 100 and 2000.
This is the result of the experiment. It shows that you should use at least 700 training runs.
{kind=link}
I’ve open sourced the sample on GitHub.
Most of the code can be re-used from the original sample. There are only two things that need to be changed in the code:
- Obtaining Hyperparameter Values from Watson
- Storing Results
Obtaining Hyperparameter Values from Watson
The values of the hyperparameters are stored in a JSON file:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from random import randint
import json
test_metrics = []
how_many_training_steps = 4000
instance_id = randint(0,9999)
try:
with open("config.json", 'r') as f:
json_obj = json.load(f)
how_many_training_steps = int(json_obj["how_many_training_steps"])
except:
pass
print('how_many_training_steps: ' + str(how_many_training_steps))
Storing Results
At the end of the training run another JSON file needs to be created which contains the test metrics. For every epoch the metrics are added:
1
test_metrics.append((i, {"accuracy": float(validation_accuracy)}))
This is the code to save the JSON file:
1
2
3
4
5
6
7
8
9
training_out =[]
for test_metric in test_metrics:
out = {'steps':test_metric[0]}
for (metric,value) in test_metric[1].items():
out[metric] = value
training_out.append(out)
with open('{}/val_dict_list.json'.format(os.environ['RESULT_DIR']), 'w') as f:
json.dump(training_out, f)
If you want to run this example yourself, get the code from GitHub and get a free IBM Cloud account. To learn more about HPO in Watson Studio, check out the documentation.