
There is a lot of talk about artificial intelligence (AI) these days, especially since Google’s AlphaGo beat a Go world champion. Companies like IBM are using this technology already in a number of products. For example on Bluemix developers can easily consume cognitive Watson services like speech or image recognition that use machine and deep learning under the cover. While these Watson services are very easy to use for developers, sometimes you want to use machine learning for other scenarios.
Since this technology looks so promising and powerful I’m trying to learn machine learning. Honestly I only started and don’t have much experience in this space but I didn’t find it too easy to get started. A lot of articles and videos seem to assume too many statistical and data skills for me as developer. There is also a wide range of different open source libraries to choose from.
However I found the open source framework Scikit Learn which seems powerful and at the same time it provides relative simple samples to get started. Below is a sample that can be run from Bluemix which identifies hand written digits. The example is documented on the Scikit Learn website. There is also a nice video which provides some additional information.
You can run this sample easily via Bluemix. I deployed a Docker container which bundles all required components and which provides a web IDE via Jupyter notebooks.
One nice thing about Scikit Learn is that it provides some sample data for your first steps in machine learning. In this case a dataset with more than 1000 images of handwritten digits is used.
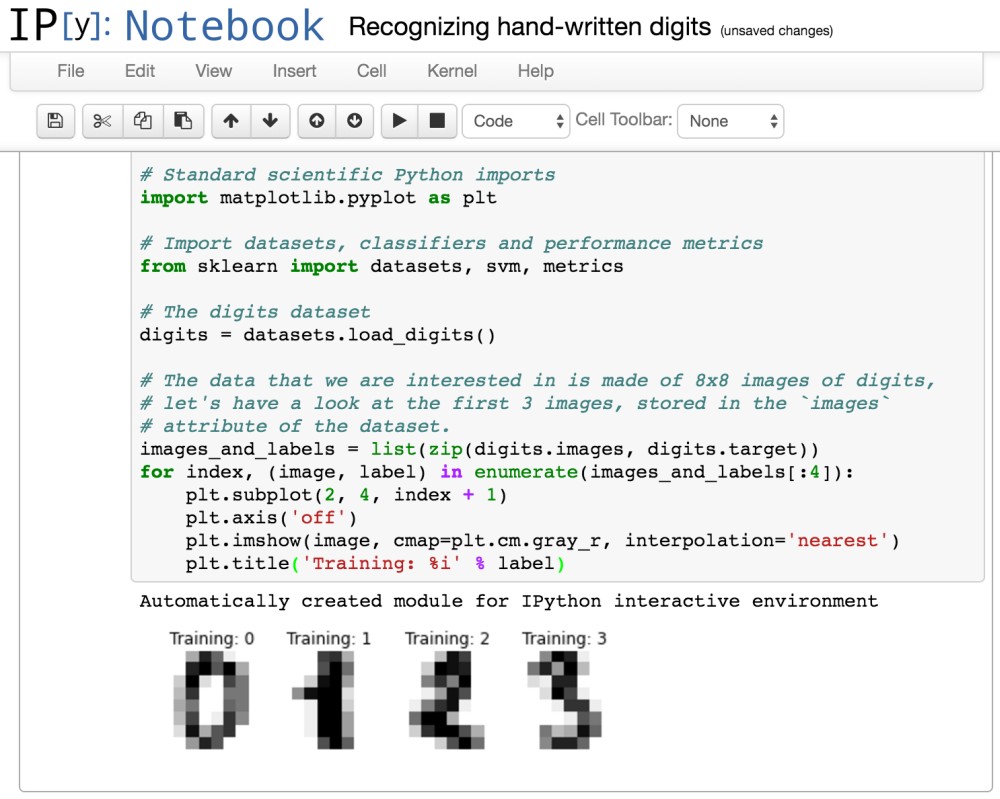
The core difference to classic programming is that you don’t code any longer rules. Instead you use algorithms that find and define rules for you based on data you need to provide. SciKit Learn provides a good amount of algorithms/classifiers which developers can use rather than having to implement these rather complex algorithms themselves. This sample uses a classifier called SVC.
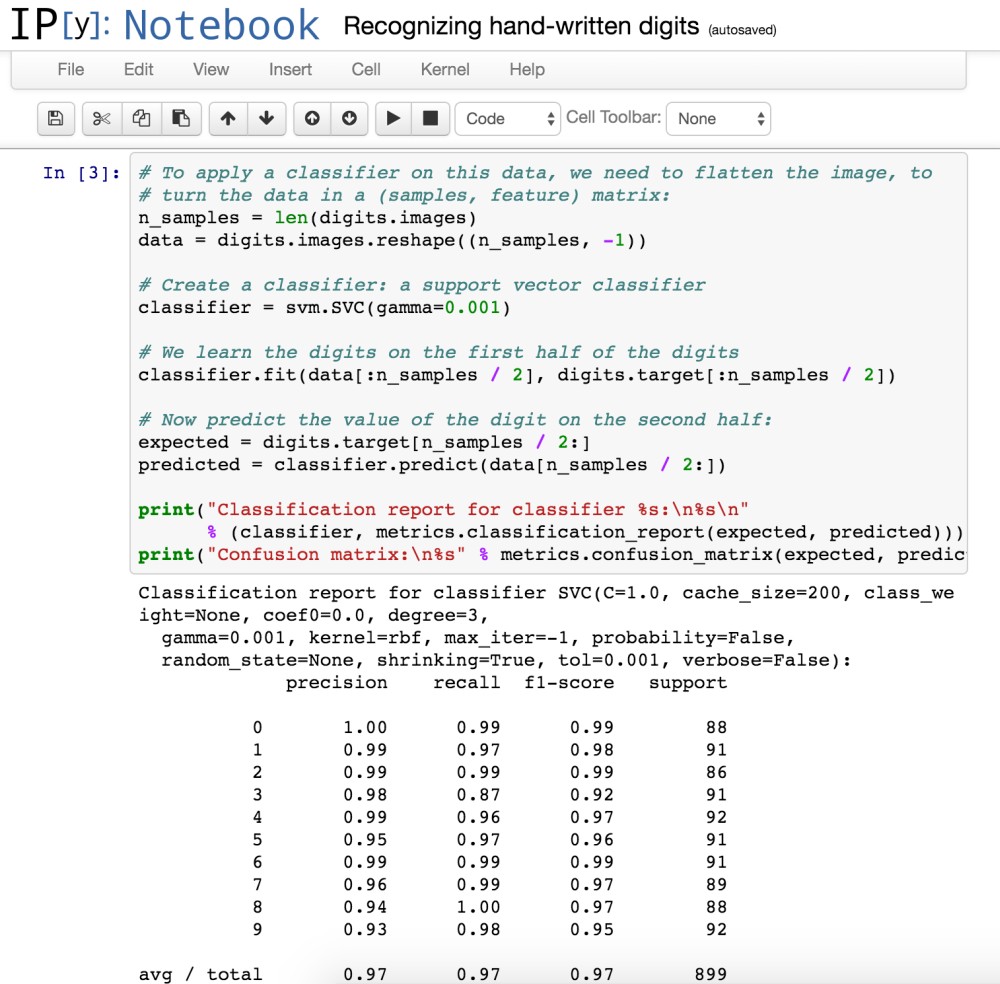
The dataset is divided in two parts. One part is used for training the classifier, the second part is used to test the predictions. As you can see the relative simple code accomplishes an accuracy of 97%.
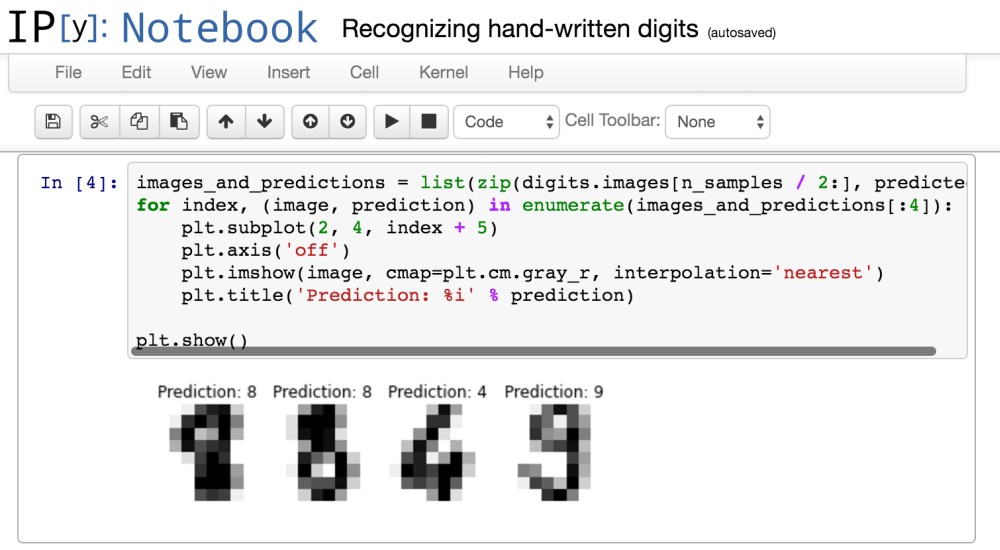
The next screenshot shows four images which were not part of the training data and for all four images the correct result is returned.
In order to run this sample on Bluemix, you can use a Docker image from my colleague Peter Parente. Here is an example how you can deploy the container to Bluemix (you need to replace the namespace):
1
2
3
4
5
docker pull parente/ipython-notebook
cf login
cf ic login
docker tag parente/ipython-notebook registry.ng.bluemix.net/nheidloff/scikit
docker push registry.ng.bluemix.net/nheidloff/scikit
After the image is available on Bluemix you can use the Bluemix UI to run the container, as done in this sample.