
I’m fascinated by the power of machine learning and I’m trying to learn more about this technology. I’ve started to look into how to use the machine learning library in Spark.
The Spark documentation of the spark.ml package explains the main concepts like pipelines and transformers pretty well. There are also a number of good videos on YouTube about machine learning. I’ve used the spark.ml library as opposed to spark.mllib since it’s the recommended approach and it uses Spark DataFrames which makes the code easier.
IBM Bluemix provides an Apache Spark service that I’ve used to run samples. The simplest way to get started is to follow the Bluemix tutorial. There is a simple sample Scala notebook to determine the top drop off locations for New York City taxis.
In addition to the taxi sample and the the simple samples in the Spark documentation there are more samples on GitHub. Make sure you use the samples of the 1.6 branch since that is the Spark version currently supported on Bluemix. I’ve chosen Scala as programming language since most of the machine learning samples I’ve seen have been written in Scala plus there are good ways to debug this code.
The Spark machine learning samples can be run on Bluemix in two different ways. Either as notebooks or as Spark applications. The advantage of notebooks is that you don’t have to set up anything. However it’s more difficult to debug code.
To run the Spark samples in notebooks you need to copy and paste only subsets of them. Let’s take the machine learning algorithm KMeans as an example. Essentially you only need the code between ‘// $example on$’ and ‘// $example off$’. In order to get the sqlContext I added ‘val sqlContext = new org.apache.spark.sql.SQLContext(sc)’ to the notebook. You also need to remove the spaces before the ‘.xxx’ when lines break since notebooks don’t seem to like this.
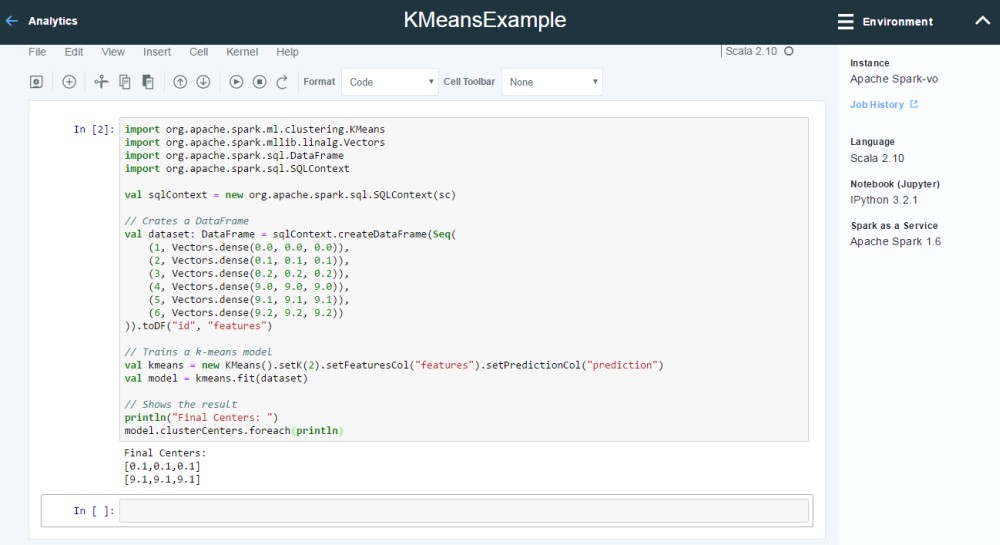
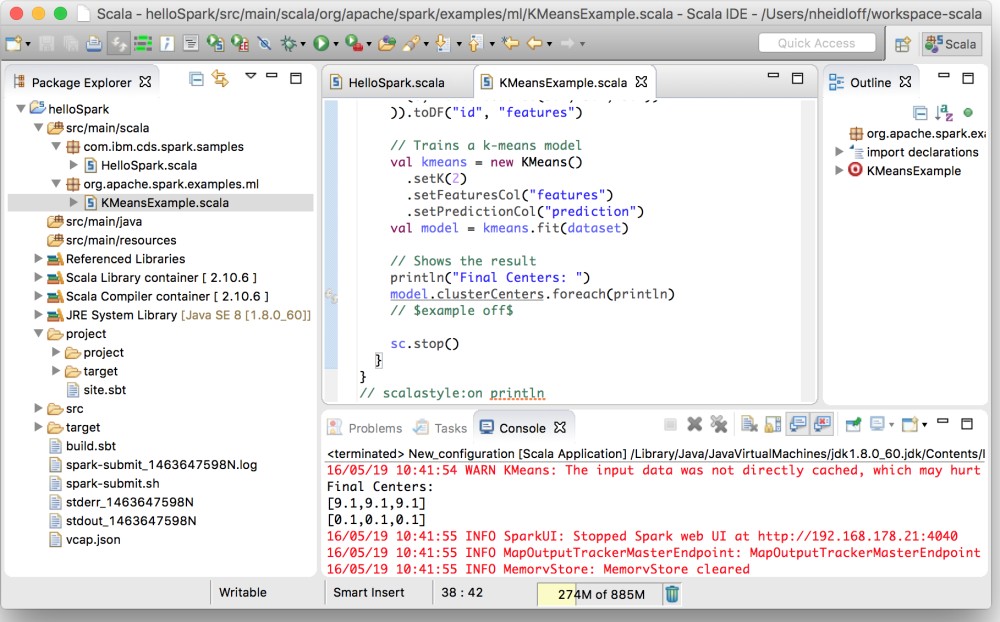
While notebooks are easy to get started, I switched to a local Scala IDE to build and run these samples. The advantage is that with a local IDE you can debug and test your code better. My colleague David Taieb describes in this article how to set up a local Scala IDE. The instructions are easy to follow. Just make sure to use the Spark version 1.6.0 in sbt.build (rather than 1.3.1).
Here is a screenshot of the same sample running in my IDE. The class name of the sample needs to be defined in the program arguments in the run configuration dialog.
In order to run the application on Bluemix use the script spark-submit.sh.
1
2
3
4
5
6
./spark-submit.sh \
--vcap ./vcap.json \
--deploy-mode cluster \
--class org.apache.spark.examples.ml.KMeansExample \
--master https://169.54.219.20 \
./target/scala-2.10/hellospark_2.10-1.0.jar file://spark-submit_20160305165113.log