
Docling is a popular open-source project contributed by IBM. It supports easy and fast parsing of PDFs and several other file types including images. This post gives a quick introduction to Docling.
Here are the high-level features from the Docling repo:
- Reads popular document formats (PDF, DOCX, PPTX, XLSX, Images, HTML, AsciiDoc & Markdown) and exports to HTML, Markdown and JSON (with embedded and referenced images)
- Advanced PDF document understanding including page layout, reading order & table structures
- Unified, expressive DoclingDocument representation format
- Easy integration with LlamaIndex & LangChain for powerful RAG / QA applications
- OCR support for scanned PDFs
- Simple and convenient CLI
Setup
The setup is very easy.
1
2
3
4
5
python3 -m venv venv
source venv/bin/activate
pip install docling
docling https://arxiv.org/pdf/2206.01062 --ocr --to json
The models are automatically downloaded from HuggingFace and are relatively small. You can run them on GPUs or CPUs.
OCR
As pdf backends pypdfium2, dlparse_v1 and dlparse_v2 are integrated. For OCR (Optical Character Recognition) EasyOCR, Tesseract, RapidOCR and Mac OCR can be utilized. The following screenshot shows how an image can be put as encoding in a markdown file and how text information is extracted to JSON.
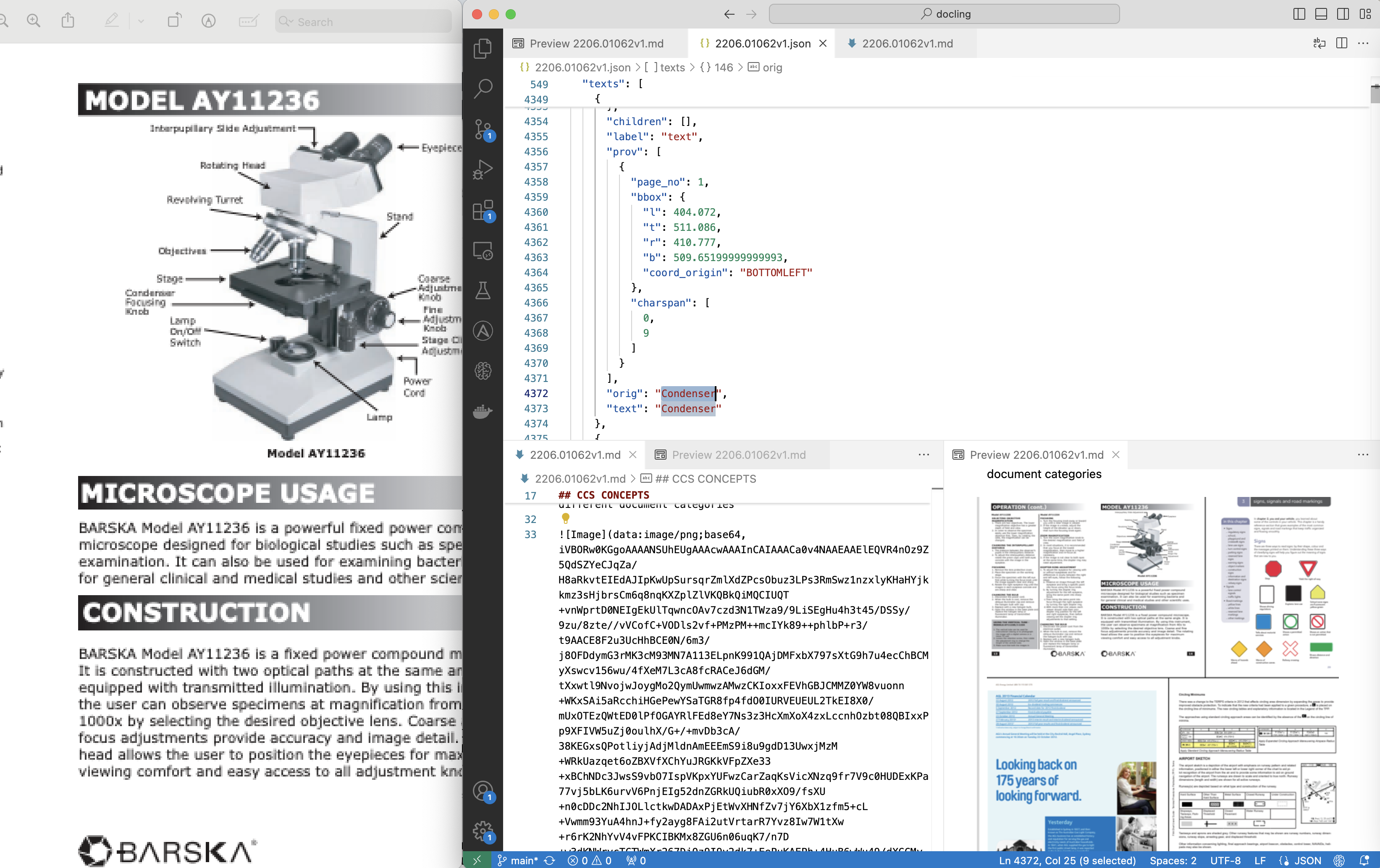
There is also an API to read the document structures.
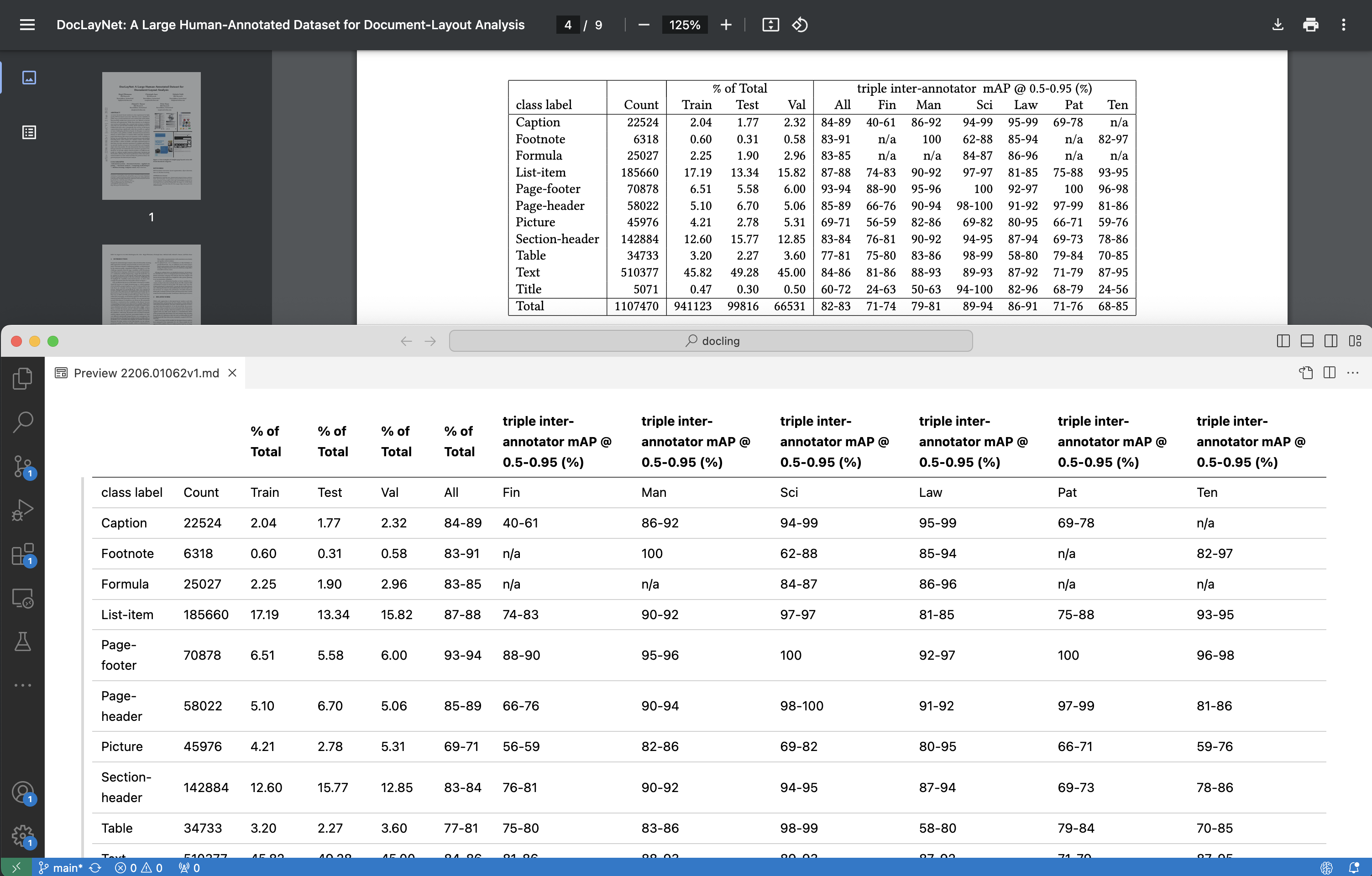
Tables
Tables can be read as well including tables that span pages.
Next Steps
The repo mentions some other forthcoming features like code and equation extractions. Check out the documentation to learn more.