
Kubernetes operators allow the automation of day 2 operational tasks. A good example is the automatic archiving of data. This article describes how data from a simple database can be archived automatically in S3 buckets using CronJobs, Jobs and custom resources.
The complete source code from this article is available in the ibm/operator-sample-go repo. The repo comes with a simple implementation of a database system which can be deployed on Kubernetes. Data is persisted in JSON files as outlined in the previous article Building Databases on Kubernetes with Quarkus.
To allow operators to backup data automatically, you need a custom resource definition first which defines when to do backups and where to store the data. We’ve created a custom resource ‘DatabaseBackup‘ with this information. We use buckets from IBM Cloud Object Storage.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
apiVersion: database.sample.third.party/v1alpha1
kind: DatabaseBackup
metadata:
name: databasebackup-manual
namespace: database
spec:
repos:
- name: ibmcos-repo
type: ibmcos
secretName: ibmcos-repo
serviceEndpoint: "https://s3.fra.eu.cloud-object-storage.appdomain.cloud"
authEndpoint: "https://iam.cloud.ibm.com/identity/token"
bucketNamePrefix: "database-backup-"
manualTrigger:
enabled: true
time: "2022-12-15T02:59:43.1Z"
repo: ibmcos-repo
scheduledTrigger:
enabled: false
schedule: "0 * * * *"
repo: ibmcos-repo
In order to run the backups on a scheduled basis, we use Kubernetes CronJobs. This makes also sense since the backup tasks can take quite some time for large datasets. The CronJob could be applied manually, but a cleaner design is to let operators do this. Secrets like the HMAC secret should also be moved to Kubernetes secrets (or security tools).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
apiVersion: batch/v1
kind: CronJob
metadata:
name: database-backup
namespace: database
spec:
schedule: "0 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: database-backup
image: docker.io/nheidloff/operator-database-backup:v1.0.7
imagePullPolicy: IfNotPresent
env:
- name: BACKUP_RESOURCE_NAME
value: "databasebackup-manual"
- name: NAMESPACE
value: "database"
- name: CLOUD_OBJECT_STORAGE_HMAC_ACCESS_KEY_ID
value: "xxx"
- name: CLOUD_OBJECT_STORAGE_HMAC_SECRET_ACCESS_KEY
value: "xxx"
- name: CLOUD_OBJECT_STORAGE_REGION
value: "eu-geo"
- name: CLOUD_OBJECT_STORAGE_SERVICE_ENDPOINT
value: "s3.eu.cloud-object-storage.appdomain.cloud"
restartPolicy: OnFailure
For testing purposes the following commands can be invoked to trigger a job manually to run immediately. In status.conditions of the database backup resource feedback is provided whether the backup has been successful.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
$ kubectl apply -f ../operator-database/config/samples/database.sample_v1alpha1_databasebackup.yaml
$ kubectl apply -f kubernetes/role.yaml
$ kubectl apply -f kubernetes/cronjob.yaml
$ kubectl create job --from=cronjob/database-backup manuallytriggered -n database
$ kubectl get databasebackups databasebackup-manual -n database -oyaml
...
status:
conditions:
- lastTransitionTime: "2022-04-07T05:16:30Z"
message: Database has been archived
reason: BackupSucceeded
status: "True"
type: Succeeded
$ kubectl logs -n database $(kubectl get pods -n database | awk '/manuallytriggered/ {print $1;exit}')
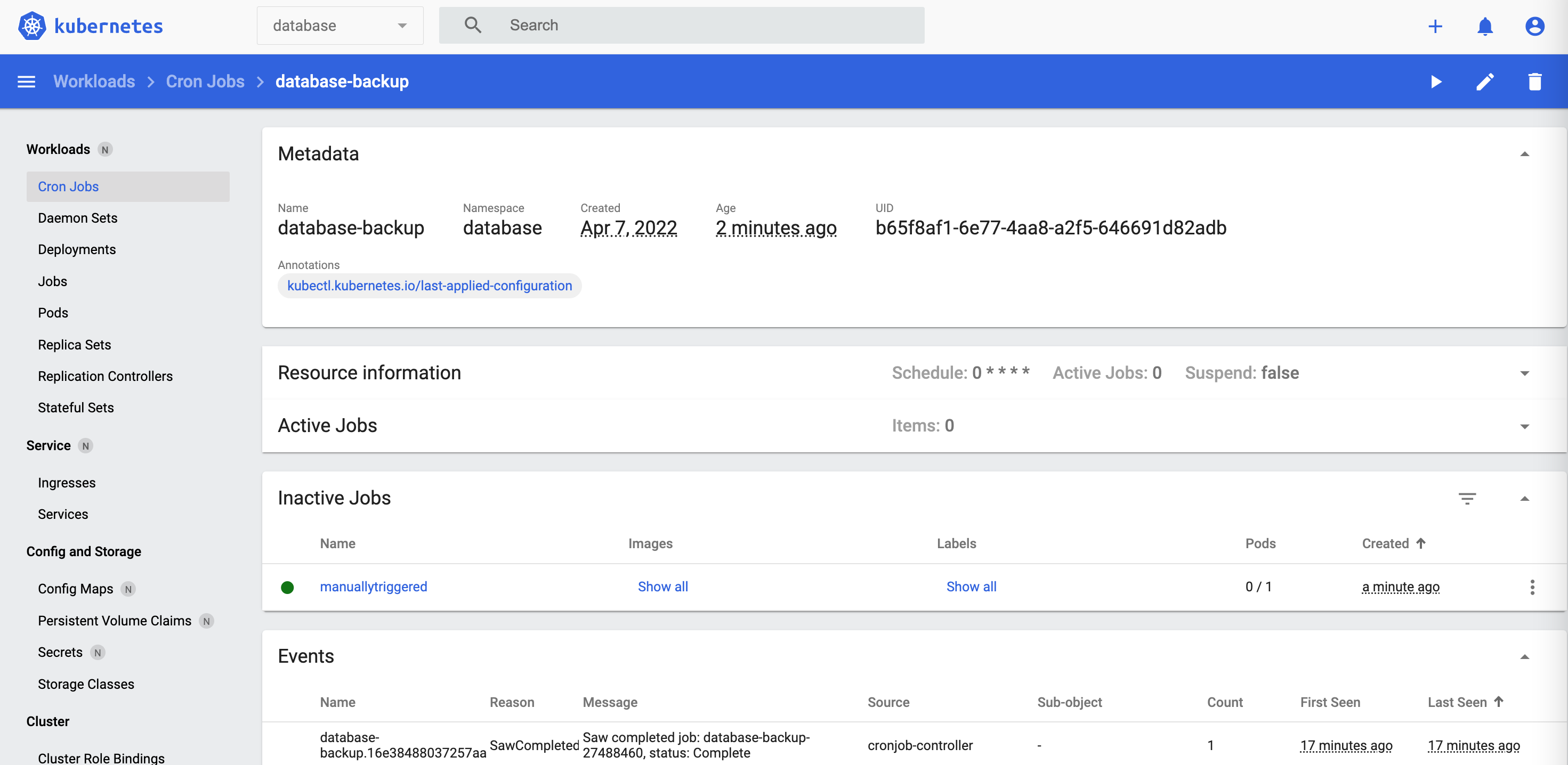
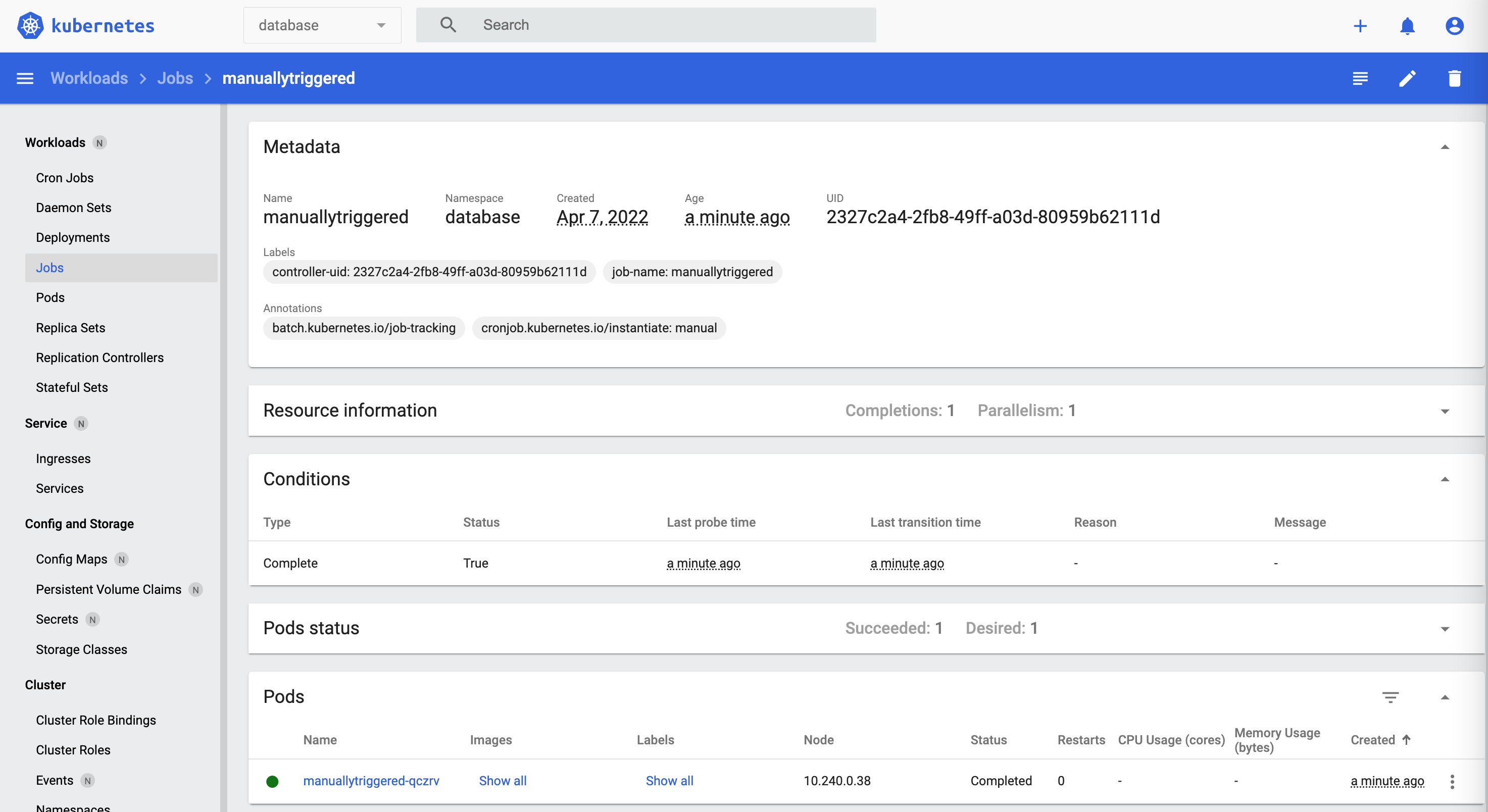
These screenshots show the deployed CronJob, Job and Pod.
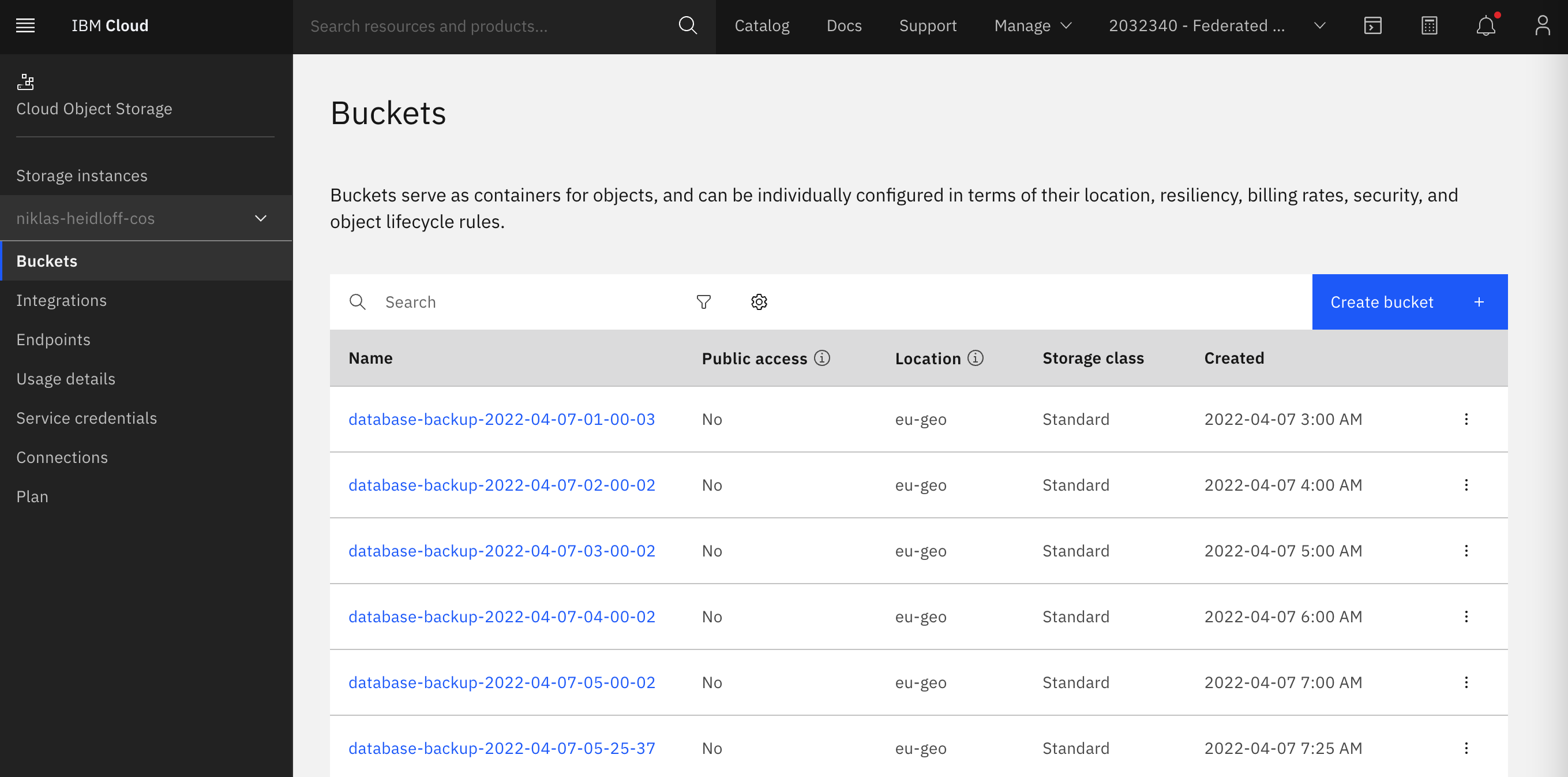
Data is archived in IBM Cloud Object Storage.
The code of the backup job is pretty straight forward. I’ve implemented a Go image with the following functionality.
- Get the database backup resource from Kubernetes
- Validate input environment variables
- Read data from the database system
- Write data to object storage
- Write status as conditions in database backup resource
To learn more about operator patterns and best practices, check out the repo operator-sample-go.