
With the new beta service Apache Spark and the support of Jupyter Notebooks in IBM Bluemix data analysts can run large scale data processing. The output can be visualized directly in the notebooks or it can be stored as files in the Swift object storage service that comes with the Bluemix Spark starter.
Alternatively you can also store the data in other data and analytics services in Bluemix. In the example below I wrote simple Scala code which uses the Apache Http Client library to invoke REST APIs from Cloudant. After this developers can for example use the Cloudant REST APIs to leverage the data in visualization tools or they can move the data to dashDB to analyze that data with advanced built-in analytics like predictive analytics and data mining.
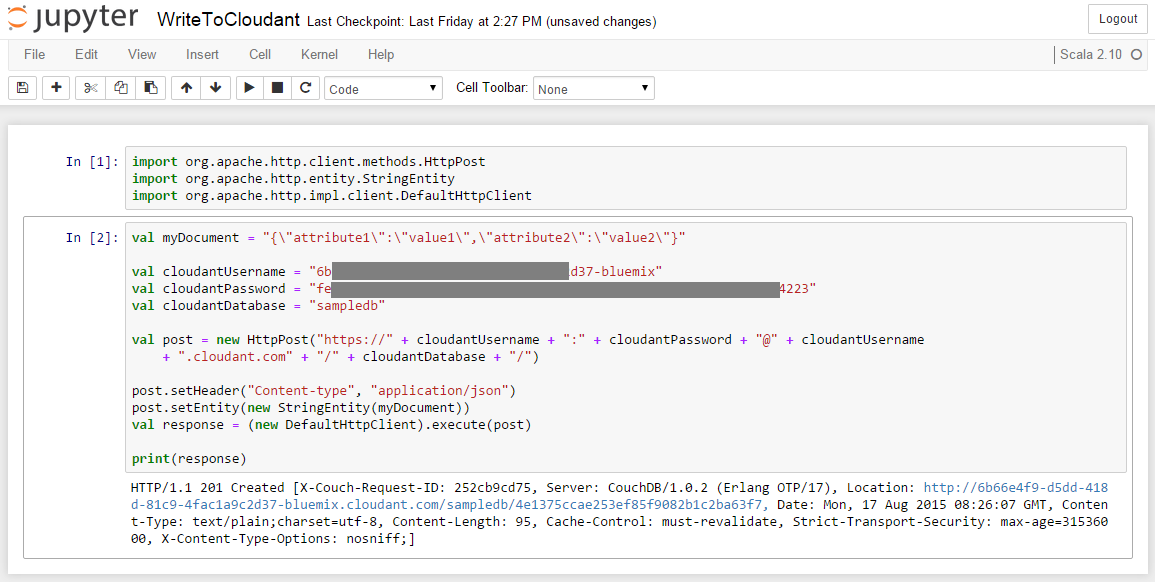
The credentials from the object storage service are available as environment variables. Credentials from other Bluemix services (from VCAP_SERVICES) can currently not be accessed via environment variables.